
※当ページのリンクには広告が含まれています。
「AIを導入したいが、何から始めればよいのか分からない」「ツールは入れたのに現場で使われない」といった悩みは多く見られます。
2026年時点では生成AIの導入が加速する一方で、ツール導入だけをDXと誤認したり、組織変革が追いつかずに活用が止まったりする失敗事例も目立つとされています。
本記事では、複数の実務者向けガイドで共通して重視されるポイントである目的の明確化、データ品質、PoC(概念実証)、現場巻き込み、運用体制を中心に、失敗を避けるための考え方を整理します。
加えて、最近のトレンドとして語られる「業務棚卸し」「AIと人の役割設計」「ROIの定量化」「小さく始めてスケール」も織り込み、実務で判断しやすい形に落とし込みます。




失敗を避ける鍵は「目的・データ・検証・現場・運用」を先に固めることです

AI導入で失敗しないための重要なポイント解説として、結論はシンプルです。
AIは魔法の道具ではないため、導入前に目的を課題ドリブンで定義し、精度を左右するデータ品質を確保し、投資前にPoCで小さく検証し、使い手である現場を巻き込み、最後に運用体制とKPI(ROI含む)を設計することが重要です。
これらを怠ると、投資回収不能や業務停滞につながる失敗が多発すると各種ガイドで指摘されています。
特に生成AIの普及に伴い、「ツールを入れれば成果が出る」という期待が先行しやすく、組織側の準備不足が失敗要因になりやすいと考えられます。
なぜこの順番が重要なのか

目的が曖昧だと「便利なだけ」の施策になりやすいです
失敗パターンとして典型的なのが、「AIで何かやりたい」から始まるケースです。
専門ブログやnoteでは、目的設定は課題ドリブンで行い、「月に何時間削減するのか」「問合せ一次回答の自己解決率を何%にするのか」といった定量目標に落とすことが推奨されています。
また、同じ便利さでも「ビタミン(あると便利)」より痛み止め(解決必須の課題)を優先するべきだという整理が複数ソースで共有されています。
目的が曖昧なままでは、評価軸が作れず、PoCの合否も判断できず、結果として「導入したが効果が説明できない」状態になりやすいと思われます。
精度問題の多くはデータ品質に起因するとされています
AIの精度低下の要因として、データの欠損、表記ゆれ、重複、ラベルの不整合などが挙げられます。
リサーチ結果では、精度低下の8割がデータ原因という指摘もあり、導入前のデータ棚卸しが重要とされています。
生成AIでも同様で、社内文書検索(RAG)やFAQ自動回答の品質は、参照させる文書の粒度・最新版管理・用語統一に大きく左右されます。
「まずモデル選定」ではなく「まずデータの健康診断」という順序が合理的です。
PoCを省くと「大規模投資の失敗」が起きやすいです
PoC(概念実証)は、AI導入の失敗ダメージを最小化するための工程と位置づけられます。
ガイドでは、大規模展開の前に小規模検証を行い、Go/No-Go基準を明文化することが推奨されています。
ここで重要なのは、PoCが「動いたら成功」ではない点です。
精度、処理時間、運用負荷、セキュリティ要件、現場の受容性など、実運用の条件を満たすかを確認しないと、本番で止まる可能性があります。
現場を巻き込まないと「使われないAI」になりやすいです
AI導入は技術導入であると同時に、仕事の進め方の変更を伴います。
そのため、現場リーダーの参加、業務フローの見直し、教育、抵抗感への配慮が必要とされています。
2026年の最新動向として、YouTube解説などでも「業務棚卸し」「AIと人の役割設計」「経営層のマインドシフト」が強調されています。
現場が「自分たちの負担が増える」と感じる設計では、定着しない可能性があります。
運用体制がないと、精度も効果も時間とともに劣化します
AIは導入して終わりではなく、運用で価値が決まります。
保守、セキュリティ、権限管理、ログ監査、プロンプトやナレッジの更新、精度モニタリングなどが必要になります。
ベンダー選定の観点でも、同業種実績の確認に加え、運用保守やセキュリティ、ROIのKPIを事前設定することが推奨されています。
また、生成AIでは100%精度を前提にしない姿勢が重要で、許容範囲と人の最終判断を含むガイドライン整備が現実的と考えられます。
実務でイメージしやすい導入パターン
例1: 「探す・まとめる・答える」を減らす生成AI活用
note記事では、日常業務の摩擦である「探す・まとめる・答える」を減らす小規模成功事例が増えているとされています。
例えば、社内規程・製品資料・過去の提案書を対象に、検索と要約を支援する仕組みをPoCで検証します。
このときのポイントは以下です。
- 目的:資料探索にかかる時間を月△時間削減する
- データ:最新版の所在、重複、機密区分、用語統一を事前に整える
- 役割分担:AIは候補提示、人が最終確認する運用にする
この領域はスモールスタートしやすく、ROIも「削減時間×人件費換算」で定量化しやすい傾向があります。
例2: コールセンターや社内ヘルプデスクの一次回答支援
FAQや過去チケットを活用し、一次回答の下書きをAIが生成し、担当者さんが確認して送る運用が考えられます。
失敗を避ける観点では、誤回答時の責任分界とエスカレーション導線を先に決めることが重要です。
PoCでは、回答正確性だけでなく、以下も確認します。
- 回答に必要な参照元が提示されるか
- 個人情報や機密情報が混入しないか
- 業務時間短縮が実測で出るか
精度期待を過度に上げず、許容範囲と人の確認を前提に設計することが現実的です。
例3: 製造・物流での予測や検知を始める前の「データ品質改善」
需要予測、異常検知、品質検査などは効果が大きい一方で、データ品質の影響を強く受けます。
そのため、いきなりモデル構築に進まず、欠損率、センサーの欠測、記録粒度、マスタ統一などを点検し、改善計画を作ることが推奨されています。
この段階は遠回りに見えますが、ガイドでは精度低下の主要因がデータであると繰り返し指摘されており、結果的に近道になりやすいと思われます。
例4: 「ツール導入だけでDX」と誤認しない進め方
最新動向として、ツール導入をDXと捉えてしまい、業務や組織が変わらず効果が出ない事例が目立つとされています。
回避策としては、導入前に業務棚卸しを行い、AI適用範囲と人の役割を設計し、経営層も含めた意思決定プロセスを整えることが挙げられます。
特に生成AIは適用範囲が広いため、ルールがないと現場ごとに使い方が分散し、セキュリティや品質の事故につながる可能性があります。

\出荷台数100万台突破!今人気のAIボイスレコーダー/


要点を押さえたチェック観点
最後に、実務で見落としやすい論点をまとめます。
- 目的:課題は定量化され、優先順位が合意されているか
- データ:欠損・表記ゆれ・重複・最新版管理・権限が整理されているか
- PoC:合否基準(Go/No-Go)と評価指標が事前に定義されているか
- 現場:現場リーダーさんが参加し、業務フロー変更が設計されているか
- 運用:保守・監査・セキュリティ・教育・KPI(ROI含む)が設計されているか
- 期待値:100%精度を前提にせず、許容範囲と人の確認が組み込まれているか
- 進め方:小さく始めてスケールするロードマップになっているか
これらは複数のガイドで共通して重視される観点であり、失敗回避に直結しやすいと考えられます。
次の一歩を取りやすくする進め方
AI導入は、壮大な構想から始めるよりも、まずは現場の摩擦が大きい業務を1つ選び、目的とKPIを置いたうえでPoCを回す方が進めやすい傾向があります。
最初の一歩としては、業務棚卸しを行い、「探す・まとめる・答える」のように時間が溶けている作業を洗い出す方法が現実的です。
そのうえで、データの所在と品質を確認し、Go/No-Go基準を決めたPoCを設計すると、投資判断もしやすくなります。
小さな成功を積み上げる設計にすることで、現場の納得感と組織学習が生まれ、結果としてスケールしやすくなる可能性があります。
【PLAUD Noto Pin】”あなたの第二の脳になる”
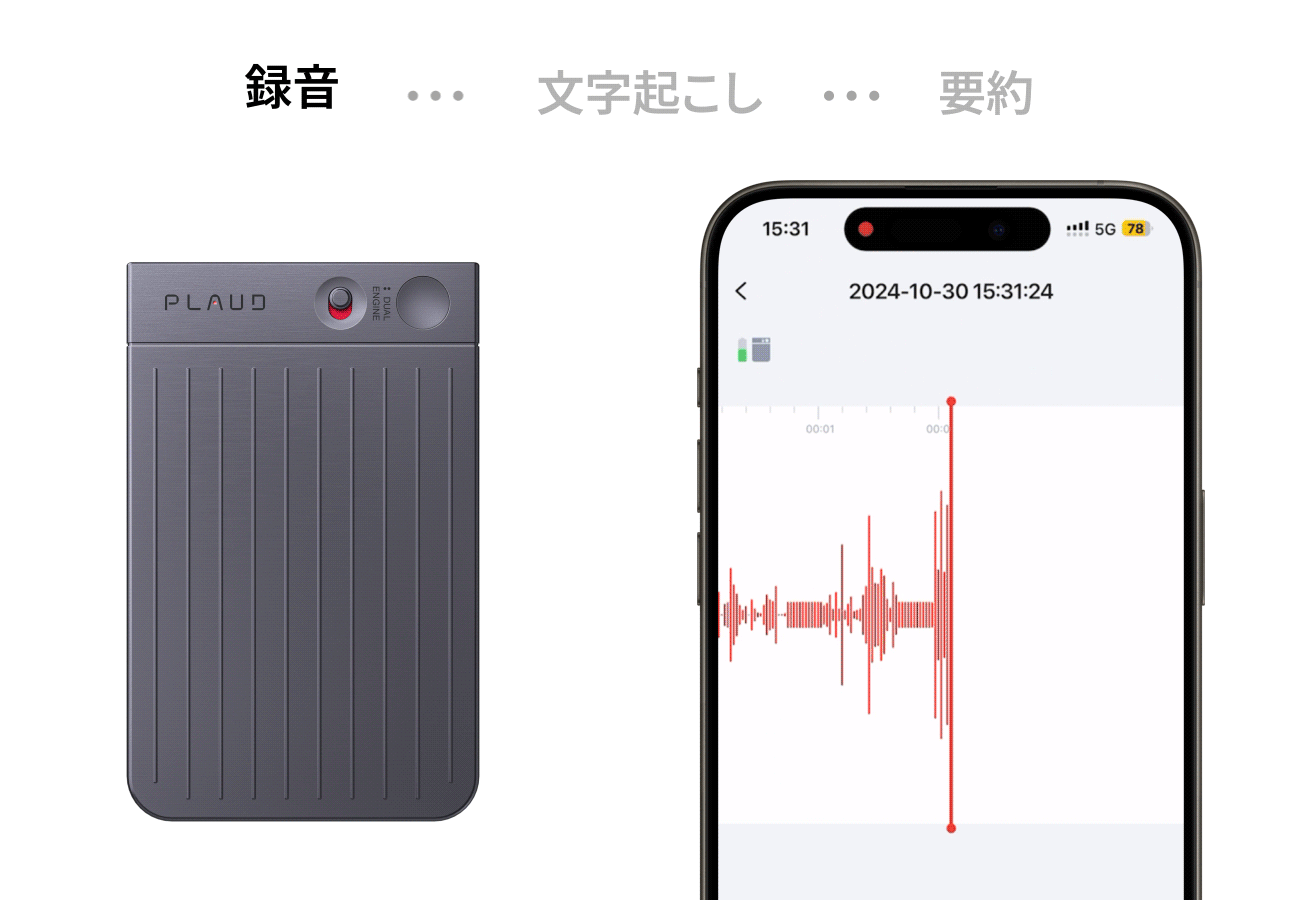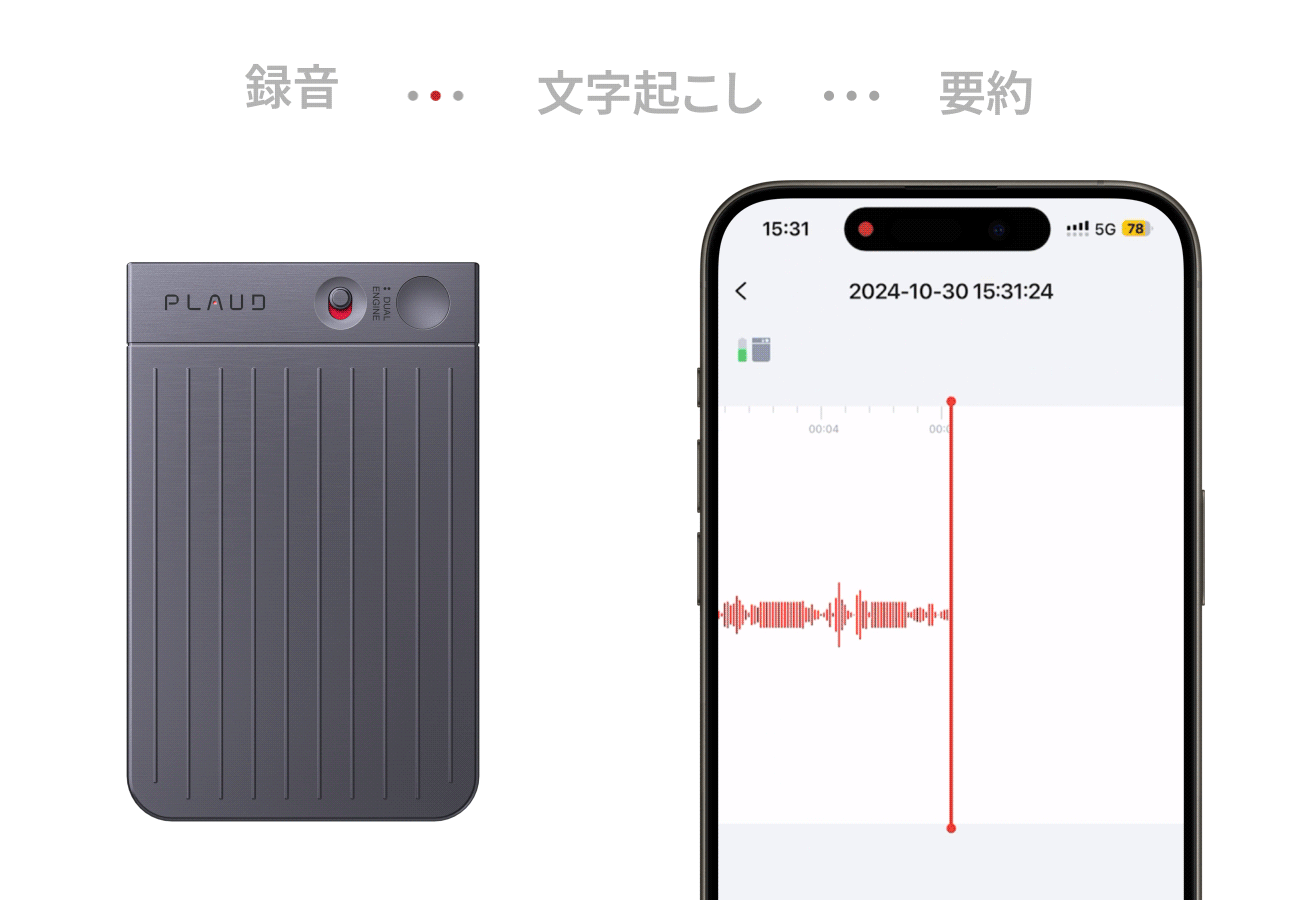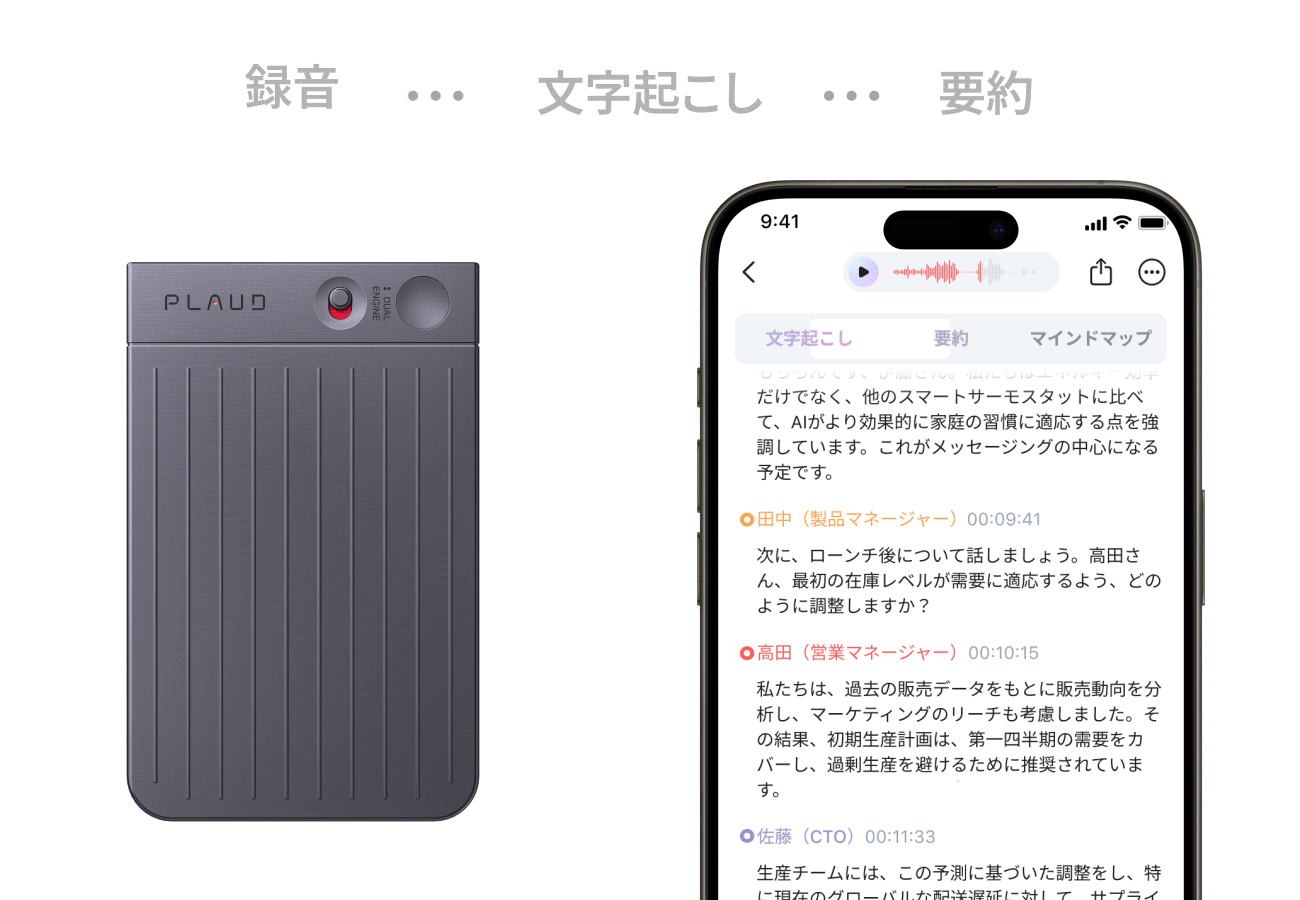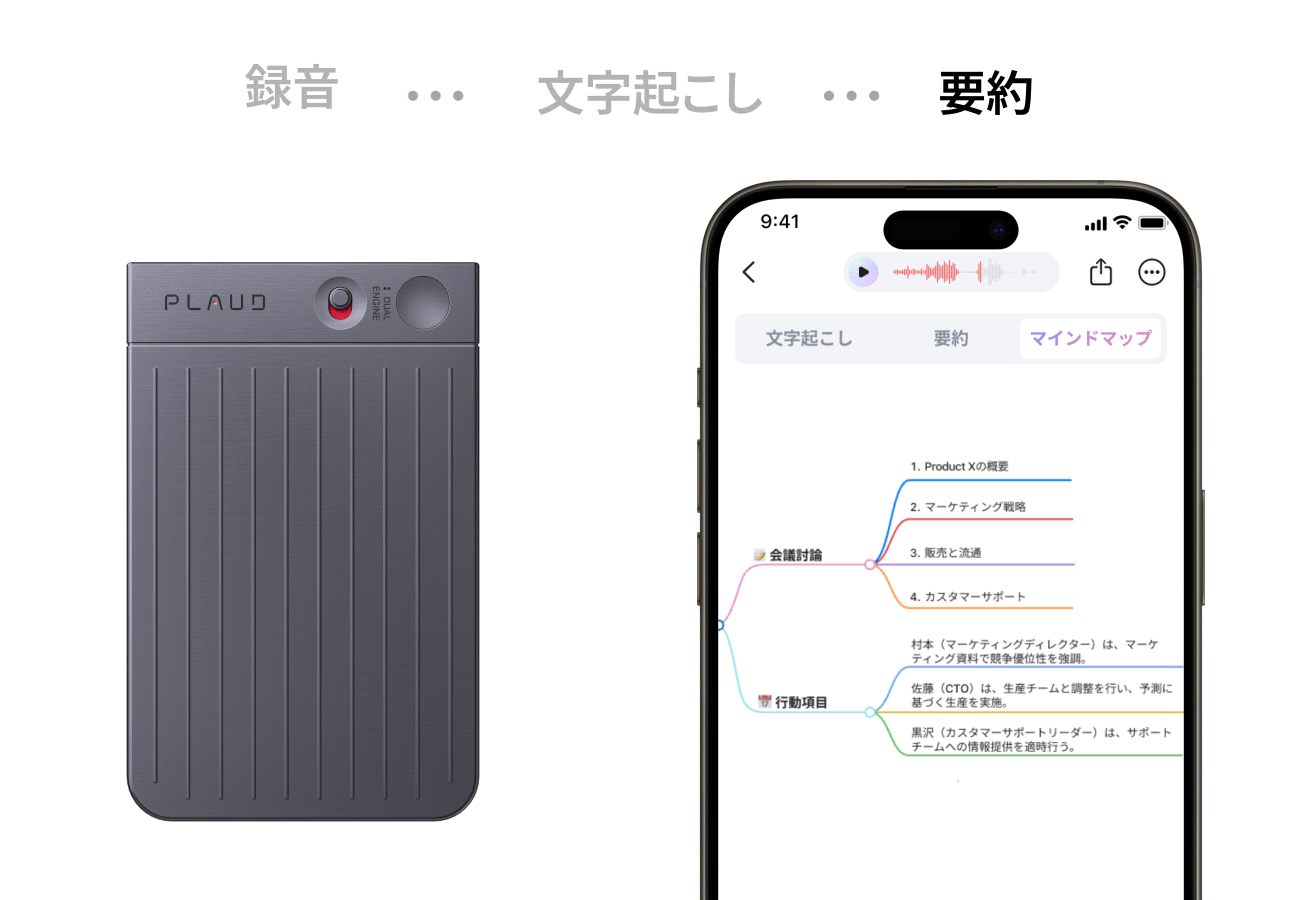
Plaud NotePin(プラウドノートピン)は、指でつまめる超小型・軽量(23g)のウェアラブルAIボイスレコーダーです。服にクリップやマグネットで装着し、日常会話、会議、取材などの音声を録音し、AIが自動で高精度な文字起こし、要約、マインドマップ化まで一貫して行います。







