
※当ページのリンクには広告が含まれています。
生成AIや各種AIツールは、文章作成、要約、検索補助、分析などを効率化し、個人にも企業にも大きな価値をもたらします。
一方で「便利そうだから」と急いで導入すると、誤情報の混入、説明できない判断、機密情報の流出、著作権などの権利侵害といった問題が表面化しやすくなります。
実際に、生成AI利用者のうち65%がハルシネーションを十分理解していない一方で、44.7%がハルシネーションを経験したという調査結果も報告されています(Forbes Japanが紹介したITSUKI調査)。
この記事では、AI活用の落とし穴を体系的に整理し、失敗しないための考え方と具体的な実務の工夫を解説します。




AI活用は「人間主導の検証」と「目的設計」が要点です

AI活用の落とし穴を避けるための要点は、AIを「判断の主体」に置かず、人間が責任を持って検証・意思決定する運用にすることです。
加えて、導入前に「何を改善したいのか」を明確化し、必要なデータ整備と業務プロセスの見直しまで含めて設計することが重要だと考えられます。
2025年3月時点のQiita記事でも、AI導入のチェックポイントとして人間主導の活用が強調され、予測結果に対する人的検証フローの実践例が挙げられています。
落とし穴が起きる背景は「AIの性質」と「運用設計不足」にあります

ハルシネーションは「それらしく誤る」ため、気づきにくいです
生成AIの代表的リスクがハルシネーションです。
AIが誤った情報を、あたかも正しい事実のように文章化するため、利用者が鵜呑みにすると業務判断を誤る可能性があります。
Forbes Japanが紹介した調査では、ハルシネーションを十分理解していない利用者が65%いる一方で、44.7%が経験済みとされています。
このギャップは、「理解不足のまま使われ、誤りが混入しやすい」状況を示唆します。
対策の基本は「検証」と「複数ソース照合」です
対策としては、AI出力をそのまま採用せず、一次情報や公的情報、複数の信頼できる情報源で照合することが推奨されます。
特に、法務・医療・金融・人事など、誤りが重大事故につながり得る領域では、人的レビューを工程として組み込む必要があります。
データバイアスとブラックボックスは「公平性」と「説明責任」を難しくします
AIは学習データの偏りを反映しやすく、結果として差別的・不公平な出力につながる可能性があります。
また、モデルの判断根拠が説明しづらい、いわゆるブラックボックス問題も、意思決定の透明性を損なう要因です。
海外の採用AIの事例が社会問題化したことも指摘されており、企業利用では責任所在の明確化が重要だと考えられます(企業ブログ等でも同趣旨の指摘があります)。
対策は「データ整備」と「説明可能性の確保」、そして責任の線引きです
学習・入力データの品質管理、評価指標の設計、監査可能なログの整備が有効です。
加えて「AIの提案は参考情報であり、最終判断は誰が行うのか」を文書化し、運用ルールとして固定することが現実的です。
情報漏洩と権利侵害は「入力」と「出力」の両方で起こり得ます
生成AIに機密情報や個人情報を入力すると、社外への漏洩リスクが高まる可能性があります。
さらに、生成物が既存著作物に類似し、著作権などの権利侵害となる懸念もあります。
この領域はツール仕様や契約条件にも左右されるため、入力ルールの設定と利用監視、そしてセキュリティ教育が重要だとされています(企業ブログ等の実務知見で多く言及されています)。
対策は「入力禁止情報の定義」と「利用環境の分離」です
社内規程として、顧客情報、未公開情報、契約情報、ソースコードなどの入力可否を明確にします。
必要に応じて、法人向けプランや閉域環境、社内ナレッジに限定した仕組みを検討することも選択肢になります。
目的不明瞭・データ不足は「導入したのに成果が出ない」典型です
中小企業の文脈では、データ整備不足による失敗パターンがトレンドとして指摘されています。
業務データが部門ごとにバラバラで、定義も統一されていない場合、AIに与える前提が崩れ、期待した精度や効果が得られない可能性があります。
また「流行しているから導入する」という動機は、目的・KPIが曖昧になりやすく、PoC止まりになりやすいと考えられます。
対策は「用途を絞る」ことと「業務プロセスを整える」ことです
最初から全社最適を狙うより、影響範囲が限定され、効果測定しやすい業務から着手する方が現実的です。
その上で、データ定義、入力手順、承認フローなどを整備し、再現性のある運用に落とし込みます。
思考停止・過度依存は「品質低下」と「責任の空洞化」を招きます
AIに丸投げすると、人間側の理解が浅くなり、誤りを見抜けない状態になり得ます。
この問題は、単にミスが増えるだけでなく、誰も結果に責任を持てない状態を生みやすい点が本質的です。
Qiitaの実践知では、AIを「優秀な部下」と見立て、上司役として人間がレビューする姿勢が強調されています。
現場で起きやすい失敗と、回避のための具体例
例1:情報収集でハルシネーションを混ぜてしまうケース
市場動向や制度変更をAIに要約させ、そのまま社内資料に貼り付ける運用では、誤情報が混入しやすくなります。
特に、出典が曖昧なまま断定口調で書かれた文章は、読み手が正しいと誤認する可能性があります。
回避策としては、次のような手順が有効です。
- 要約対象の一次情報(官公庁資料、規約原文、決算資料など)を先に確保します
- AI出力には出典URLや根拠箇所の提示を求めます
- 重要な数字・日付・固有名詞は、人間が原文で照合します
例2:採用・評価でバイアスが疑われるケース
応募者の文章や経歴をAIでスコアリングし、足切りに使う設計は、バイアスの影響が顕在化しやすい領域です。
学習データの偏りや評価項目の設計次第で、特定属性に不利な結果が出る可能性があります。
回避の要点は「AIを決定者にしない」ことです。
- AIの出力は「補助的な観点」に限定し、最終判断は人間が行います
- 評価基準を文章化し、説明可能な形で保存します
- 定期的に結果を検証し、偏りがないかを点検します
例3:社内で機密情報を入力してしまうケース
議事録の整形、提案書の推敲、コードレビューなどで、うっかり顧客名や契約条件、未公開の数値を入力してしまうことがあります。
悪意がなくても、入力行為そのものが規程違反や漏洩リスクになる可能性があります。
回避策としては、運用ルールと教育のセットが重要です。
- 入力禁止情報(個人情報、顧客識別子、未公開情報など)を具体例付きで定義します
- 匿名化・マスキングの手順をテンプレート化します
- 利用ログの確認や、利用ツールの統制(アカウント管理)を行います
例4:目的が曖昧なまま導入し、PoCで止まるケース
「AIで生産性を上げたい」という抽象的な目標だけで導入すると、現場が何を変えればよいか分からず、定着しにくい傾向があります。
中小企業では、そもそもデータが整っていないため、AI以前の問題としてつまずくケースも指摘されています。
回避策は、スコープを絞って成果の出る形にすることです。
- 対象業務を1つに絞り、KPI(作業時間、ミス率、対応件数など)を決めます
- 入力データの所在と形式を確認し、最低限の整備を行います
- 運用後もモニタリングし、改善サイクルを回します

\出荷台数100万台突破!今人気のAIボイスレコーダー/


AI活用の落とし穴を避けるための要点整理
AI活用の落とし穴は、技術の問題だけでなく、運用設計と責任設計の不足から起きることが多いと考えられます。
特に注意したいポイントは次のとおりです。
- ハルシネーションは起こり得る前提で、出力検証と複数ソース照合を行います
- バイアスとブラックボックスに備え、説明責任と責任所在を明確にします
- 情報漏洩・権利侵害は入力と出力の両面で対策し、ルールと教育を整えます
- 目的不明瞭・データ不足を避け、用途を絞ってデータと業務プロセスを整備します
- 思考停止を防ぎ、AIを補助ツールとして人間が上司役でレビューします
Qiitaで強調されるように、現場検証と追跡監視の仕組みを持つことが、導入失敗を避ける現実的なアプローチだと考えられます。
小さく始めて検証し、安心して広げていくために
AIは、正しく使えば業務の質と速度を同時に高める可能性があります。
一方で、誤情報、偏り、漏洩、権利侵害といった落とし穴は、対策なしでは現実に起こり得ます。
最初の一歩としては、用途を1つに絞り、「人間が検証して責任を持つ」フローを先に作ることが有効です。
その上で、入力ルール、ログ、レビュー観点、判断基準を整備し、段階的に適用範囲を広げていくと、失敗確率を下げながら成果につなげやすくなると思われます。
【PLAUD Noto Pin】”あなたの第二の脳になる”
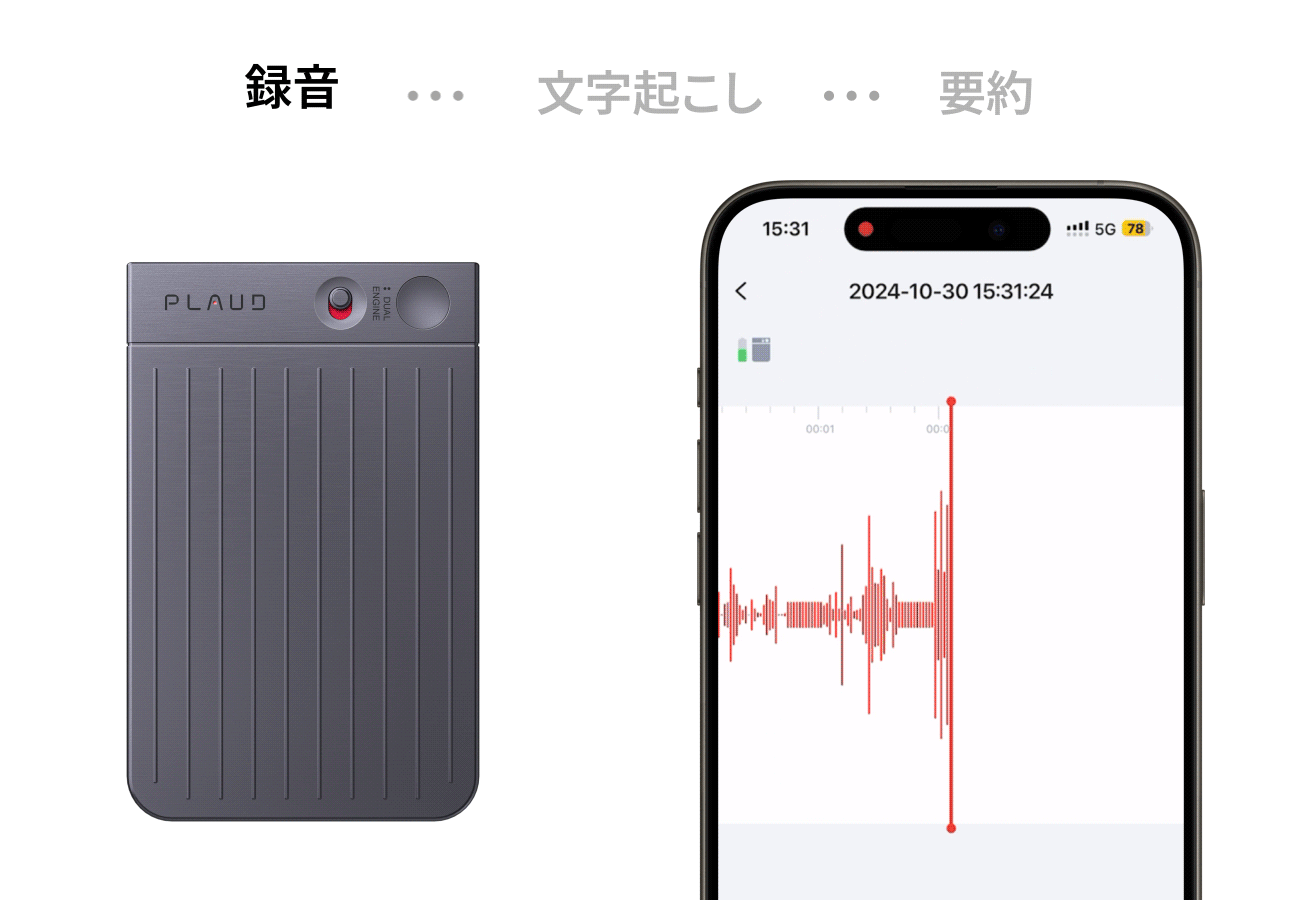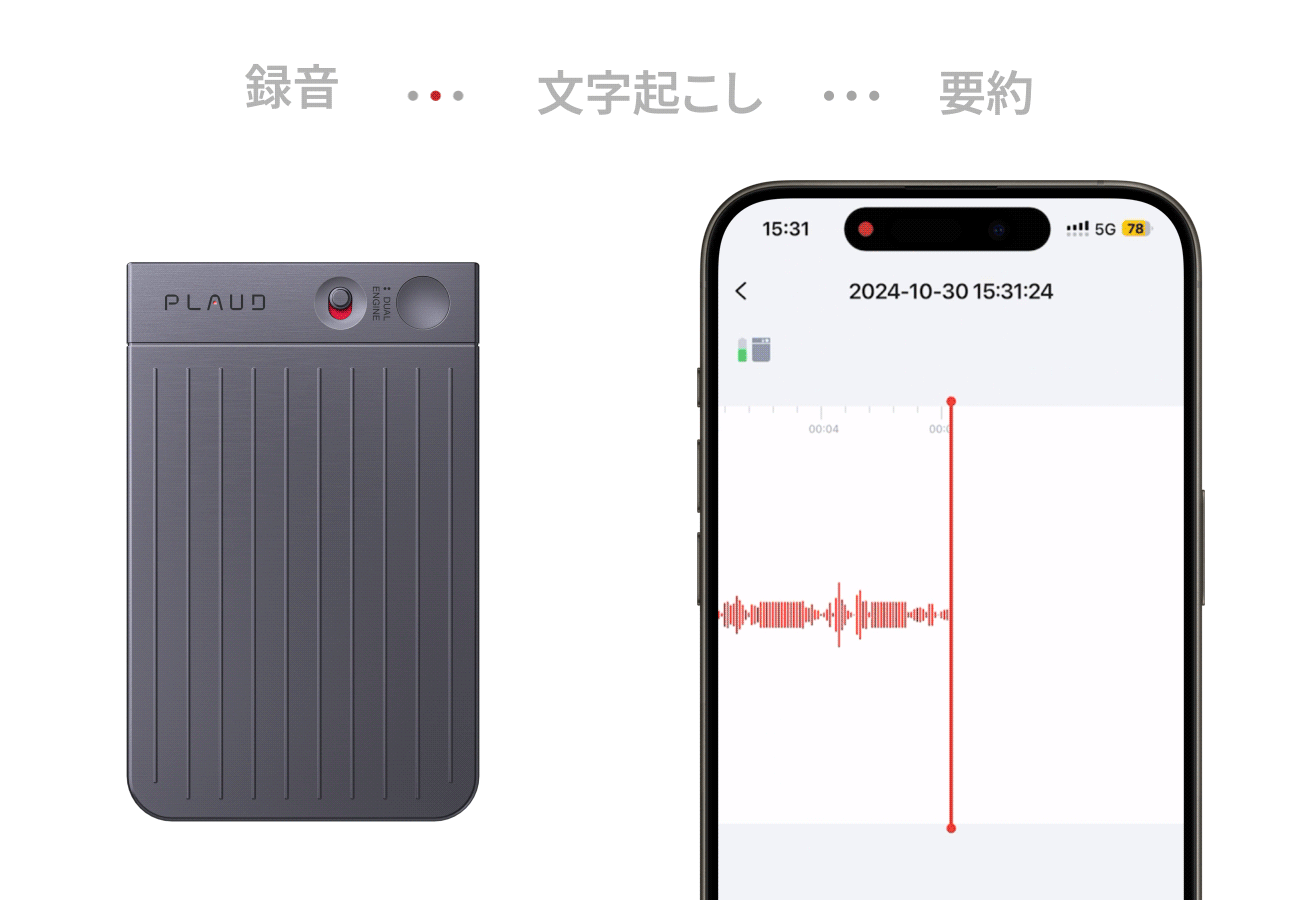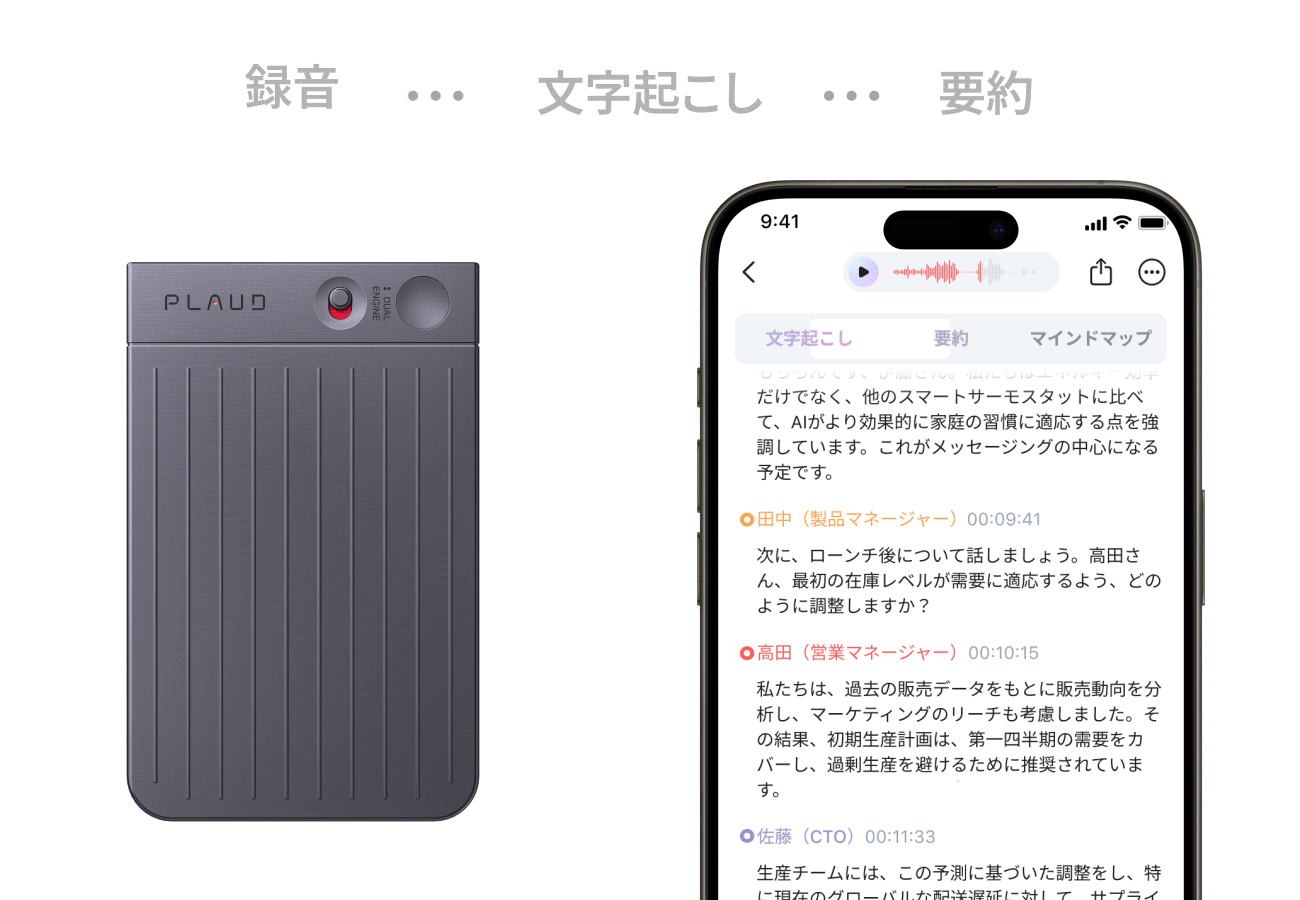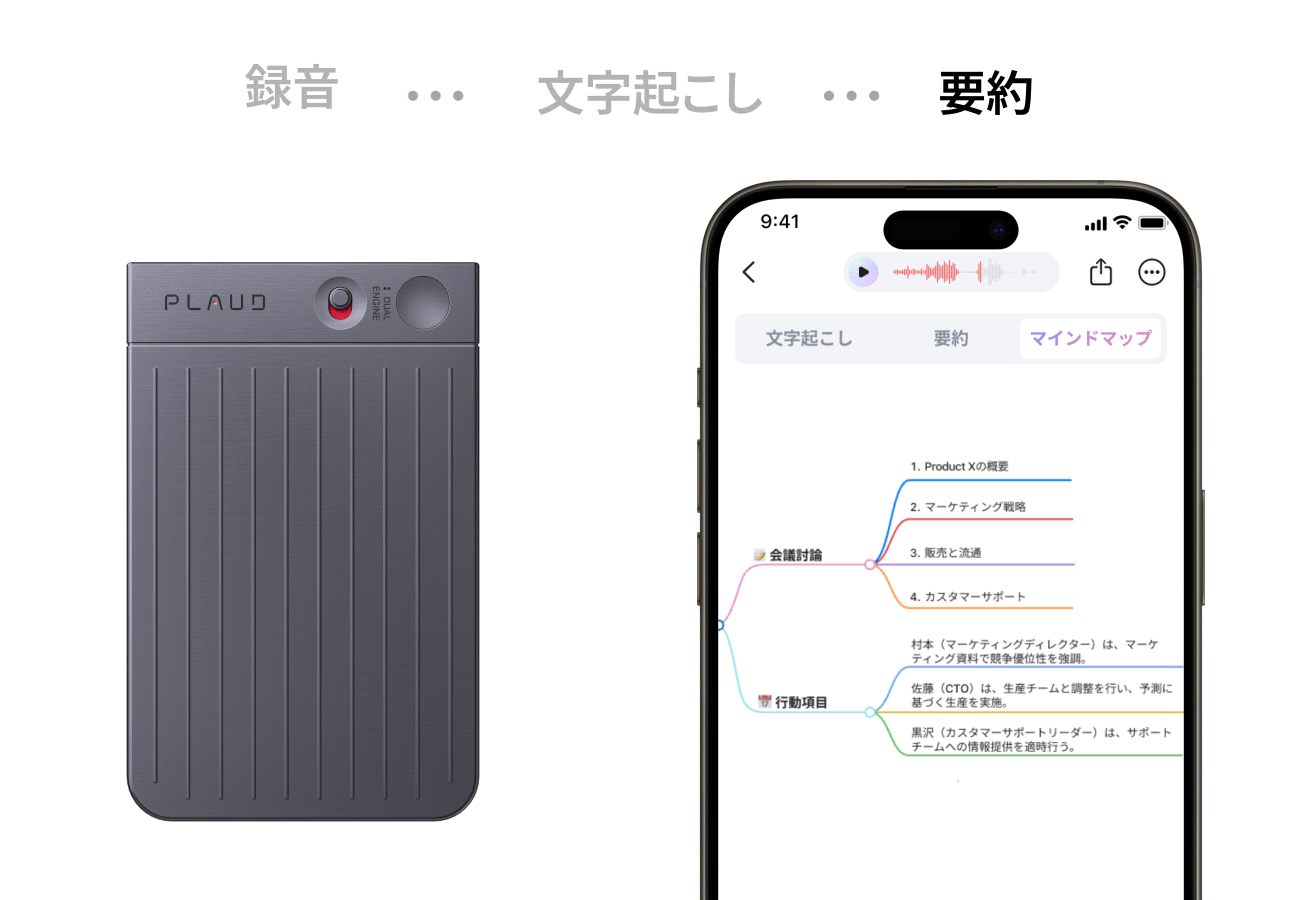
Plaud NotePin(プラウドノートピン)は、指でつまめる超小型・軽量(23g)のウェアラブルAIボイスレコーダーです。服にクリップやマグネットで装着し、日常会話、会議、取材などの音声を録音し、AIが自動で高精度な文字起こし、要約、マインドマップ化まで一貫して行います。







