
※当ページのリンクには広告が含まれています。
AI導入は、うまくいけば業務効率化や品質向上につながる一方で、「試したが定着しない」「PoC(概念実証)で終わる」「期待したほど効果が出ない」といった悩みも多いテーマです。
特に生成AIの普及以降、スピード感を優先して着手した結果、データ不足や運用設計の甘さ、ハルシネーション(幻覚)や機密情報の取り扱いでつまずくケースが増えているとされています。
本記事では、国内外の失敗事例と調査結果を手がかりに、失敗が起きる構造を整理します。
そのうえで、目的設定、データ品質、現場巻き込み、セキュリティ、効果測定まで含めた「成功確率を上げる進め方」を具体的にまとめます。




成功のポイントは「目的・データ・運用」を最初にそろえることです

AI導入の成功確率を上げる要点は、目的(KPI)・データ(品質)・運用(現場とガバナンス)を初期段階でそろえることです。
技術選定やモデル精度の議論は重要ですが、それ以前に「何を改善したいのか」「その改善を測る指標は何か」「本番データと業務フローで回るのか」を決めないまま進むと、PoC止まりや形骸化が起きやすいと考えられます。
実際、MIT Sloanの報告では、パイロットプロジェクトの95%が成果ゼロという厳しいデータが示されています。
また、2025年のGartner調査では、AI対応データが不足する組織は2026年までにAIプロジェクトの60%を断念する見通しが示されており、データ基盤の重要性が改めて強調されています。
失敗が起きやすい理由は「PoCの成功条件」と「本番の現実」が違うためです

目的が曖昧だと、評価も改善もできません
「競合が導入しているから」「とりあえずAIを試したい」といった動機で始めると、成果の定義が曖昧になりやすいです。
その結果、PoCで一定の精度が出ても、何がどれだけ良くなったのかを説明できず、投資判断が止まる可能性があります。
対策としては、業務課題を具体化し、KPIを明確にすることが基本です。
例えば「問い合わせ一次対応の平均処理時間を20%短縮」「審査書類の差戻し率を10%削減」など、業務に紐づく指標に落とし込むことが有効とされています。
PoCは「きれいな小データ」で勝ちやすく、本番は別ゲームになりがちです
PoCでよくある落とし穴は、限定されたデータ、限定された利用者、限定された業務範囲で成立していた成功が、本番環境では再現しない点です。
本番では、データ量の増加、例外処理、既存システム連携、権限管理、監査対応などが加わります。
このギャップが埋められないと、いわゆる「PoC貧乏」に陥り、検証だけが積み上がって運用に到達しない状態になりやすいと考えられます。
調査・分析でも、PoCが成果に結びつきにくい現状が指摘されています。
データ不足・データ品質の問題が、精度以前に失敗を招きます
AIはデータが前提です。
しかし現場の実態として、入力揺れ、欠損、部門ごとの定義違い、ラベル品質のばらつきなどが残ったまま学習・評価してしまうことがあります。
また、データに偏りがあると、差別的・不公平な判断を強化してしまうリスクがあります。
海外事例として、Amazonの履歴書選考AIが女性に不利な傾向を示した事例は、バイアスが実務上の重大リスクになり得る点を示しました。
近年はXAI(説明可能AI)を活用し、なぜその判断になったのかを説明できる状態を作る動きがトレンドとされています。
現場不在だと、使われずに終わる可能性があります
経営層主導やDX部門単独で進めると、現場の業務フローや例外処理が反映されにくくなります。
その結果、現場の担当者さんが「手間が増えた」「責任だけ増えた」と感じ、利用が定着しないことがあります。
全社一斉展開よりも、1チーム×1業務のように小さく始め、現場でのフィット感を確認しながら広げる進め方が推奨されます。
生成AIは便利ですが、ハルシネーションと機密漏洩が現実的な課題です
生成AIは文章作成や要約、問い合わせ対応などに適用しやすい一方、誤情報をそれらしく生成するハルシネーションが避けにくいとされています。
さらに、プロンプトに機密情報を入力してしまう運用は、情報漏洩リスクにつながります。
音声AIの運用が期待通りにいかなかった事例として、マクドナルドの音声AIに関する失敗例が取り上げられることもあり、運用設計と品質管理の重要性が示唆されます。
対策としては、人間による検証を前提にしたHITL(Human-in-the-loop)や、利用ログ監査、アクセス制御、プロンプトガイドライン整備が重要です。
「内製すべき領域」と「外部サービスで十分な領域」を見誤ると消耗します
RAG(検索拡張生成)やAI-OCRなど、一定の成熟が進んだ領域はパッケージやクラウドサービスの活用が合理的な場合があります。
すべてを内製すると、モデル改善よりも基盤整備や運用保守に工数が吸収され、肝心の業務価値が出る前に疲弊する可能性があります。
差別化につながる部分に内製リソースを集中し、コモディティ領域は外部活用する方針が現実的と考えられます。
失敗事例から学ぶ具体例(対策まで含めて整理)
事例1:チャットボット導入が「回答できないボット」になったケース
国内でも、チャットボットが期待通りに機能せず、利用者さんの不満につながった事例が報告されています。
背景としては、FAQの整備不足、最新情報への追随遅れ、問い合わせ分類の設計不備などが重なり、ボットが適切に回答できない状態になった可能性があります。
対策としては、以下が挙げられます。
- KPIの設定(自己解決率、有人転送率、CSスコアなど)
- RAGで社内ナレッジを参照し、回答根拠を示す設計
- HITLで誤回答を検知し、改善ループを回す運用
事例2:PoCは成功したのに、本番で精度が落ちて頓挫したケース
PoCでは「整ったデータ」「例外の少ない業務」だけを対象にすることが多いです。
そのため、本番でデータの欠損や入力揺れ、部門間の定義差、システム連携の遅延が発生すると、精度や処理速度が想定を下回る可能性があります。
対策としては、PoCの段階から本番に近い条件を織り込むことが重要です。
- 本番データのサンプルで評価し、データクレンジング工数を見積もる
- 例外処理・手戻りを含む業務フローで検証する
- 小規模でも「本番運用」まで到達させ、横展開する
事例3:採用・審査などでバイアスが問題化したケース
Amazonの履歴書選考AIの事例は、過去データの偏りがモデルに反映され、特定属性に不利な判断を強めたとされています。
この種の領域では、精度だけでなく、公平性や説明責任が強く求められます。
対策としては、以下が現実的です。
- 学習データの偏りを点検し、評価指標に公平性指標を含める
- XAI(説明可能AI)で判断根拠を追跡可能にする
- 最終判断は人が行うHITLを前提に、監査ログを残す
事例4:生成AIの誤回答や機密情報の取り扱いで運用停止したケース
生成AIは、正しそうに見える誤回答を出すことがあります。
また、社内情報を入力したプロンプトが外部に流出する懸念が指摘されるなど、セキュリティ面の設計が不十分だと運用停止に至る可能性があります。
対策としては、技術とルールの両輪が必要です。
- 入力禁止情報の定義、権限管理、ログ監査の整備
- 回答に根拠リンクを添えるRAG設計、もしくは根拠不明の回答を抑制するガードレール
- 重要業務では人間の確認を必須化し、誤りの影響を局所化する

\出荷台数100万台突破!今人気のAIボイスレコーダー/


要点を押さえると、AI導入は「再現性のある投資」になりやすいです
AI導入の失敗は、技術力不足というより、目的・データ・運用の設計不足で起きることが多いと考えられます。
特に重要なのは、次の観点です。
- 目的の明確化:業務課題をKPIに落とし、投資判断できる状態にする
- PoCから本番化:小さく始めつつ、本番条件で回るかを早期に検証する
- データ品質確保:量と質、偏り、定義を点検し、XAIも活用する
- 現場巻き込み:現場の担当者さんと改善ループを作り、定着まで見る
- 過度な期待回避:精度80〜90%を前提にHITLで運用品質を担保する
- セキュリティと効果測定:後回しにせず、継続モニタリングを組み込む
これらは、MIT Sloanのパイロット成功率の厳しさや、Gartnerが指摘するデータ不足リスクとも整合する実務的な論点です。
次に取るべき行動は「1業務の設計書」を作ることです
最初の一歩としては、全社横断の壮大な構想よりも、1チーム×1業務で「目的・データ・運用」を一枚に整理することが有効です。
例えば、次の項目を短い文書にして関係者さんで合意すると、PoC貧乏を避けやすくなります。
- 対象業務と、解決したい困りごと
- KPI(現状値、目標値、測定方法)
- 使うデータ(所在、品質課題、更新頻度、権限)
- 運用(誰が使い、誰が直し、誰が止めるか)
- セキュリティ(入力制限、ログ、監査)
この整理ができると、ツール選定や内製・外製の判断も現実的になります。
結果として、AI導入が「試して終わる取り組み」ではなく、継続的に改善できる業務基盤として育ちやすくなると考えられます。
【PLAUD Noto Pin】”あなたの第二の脳になる”
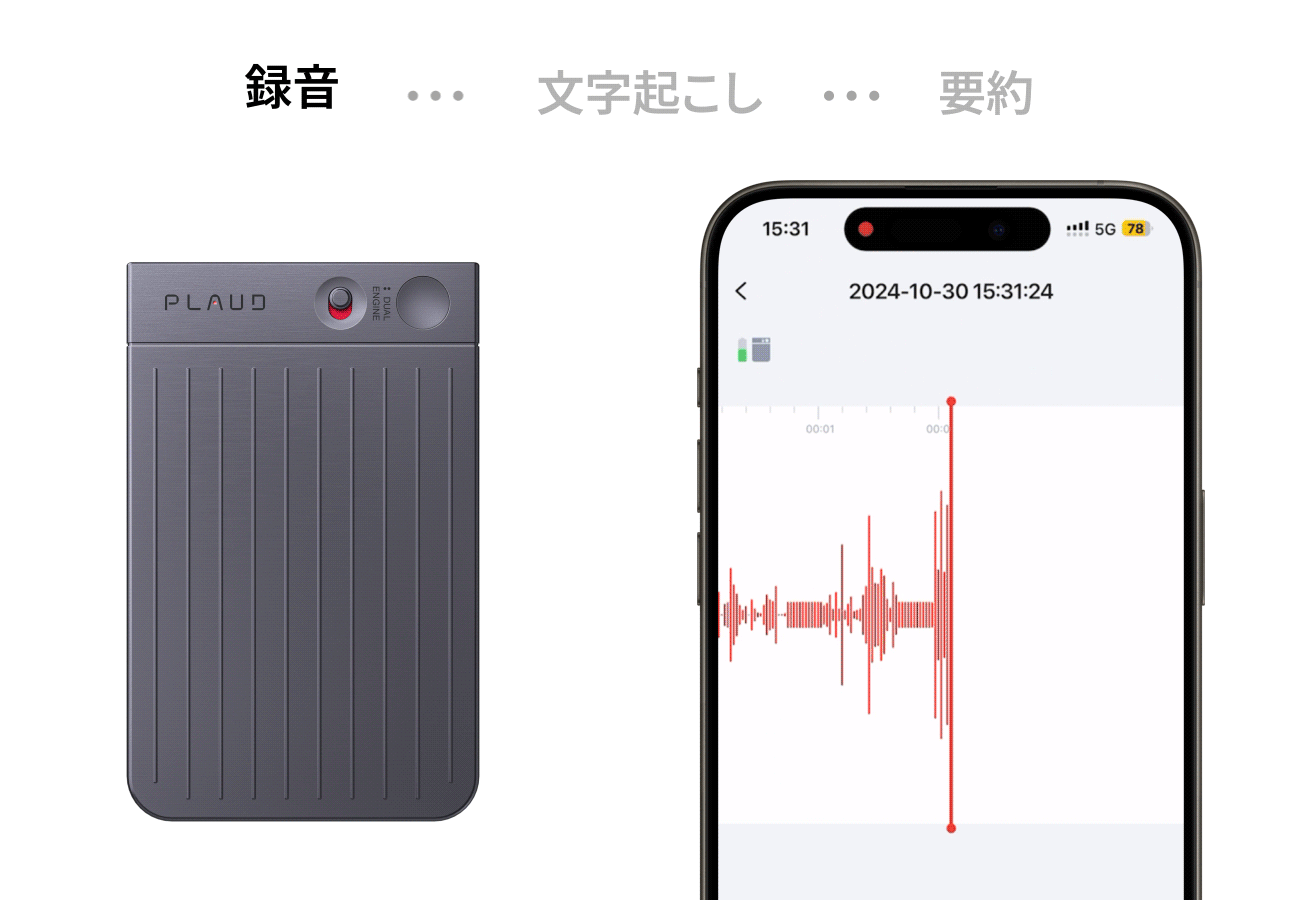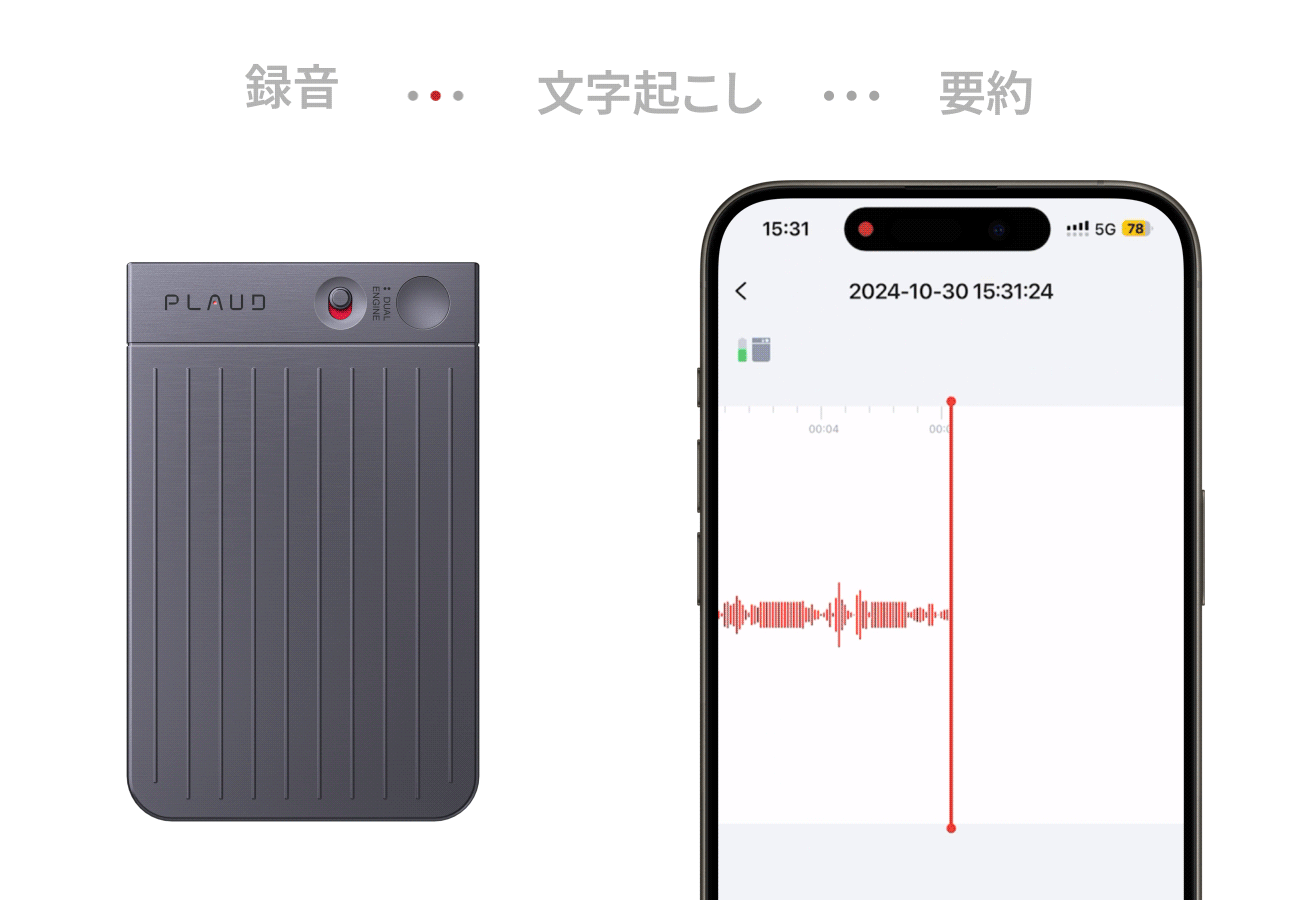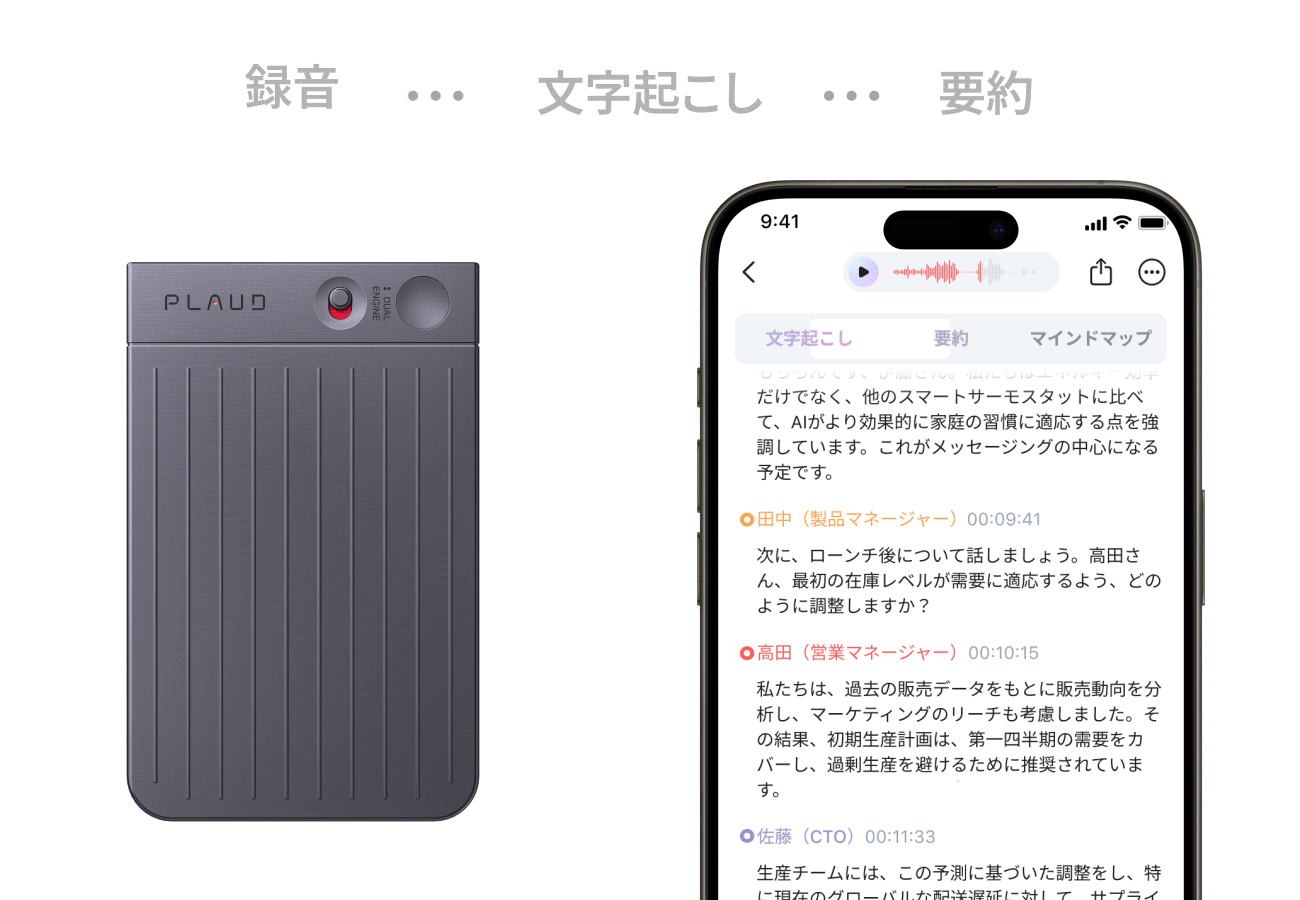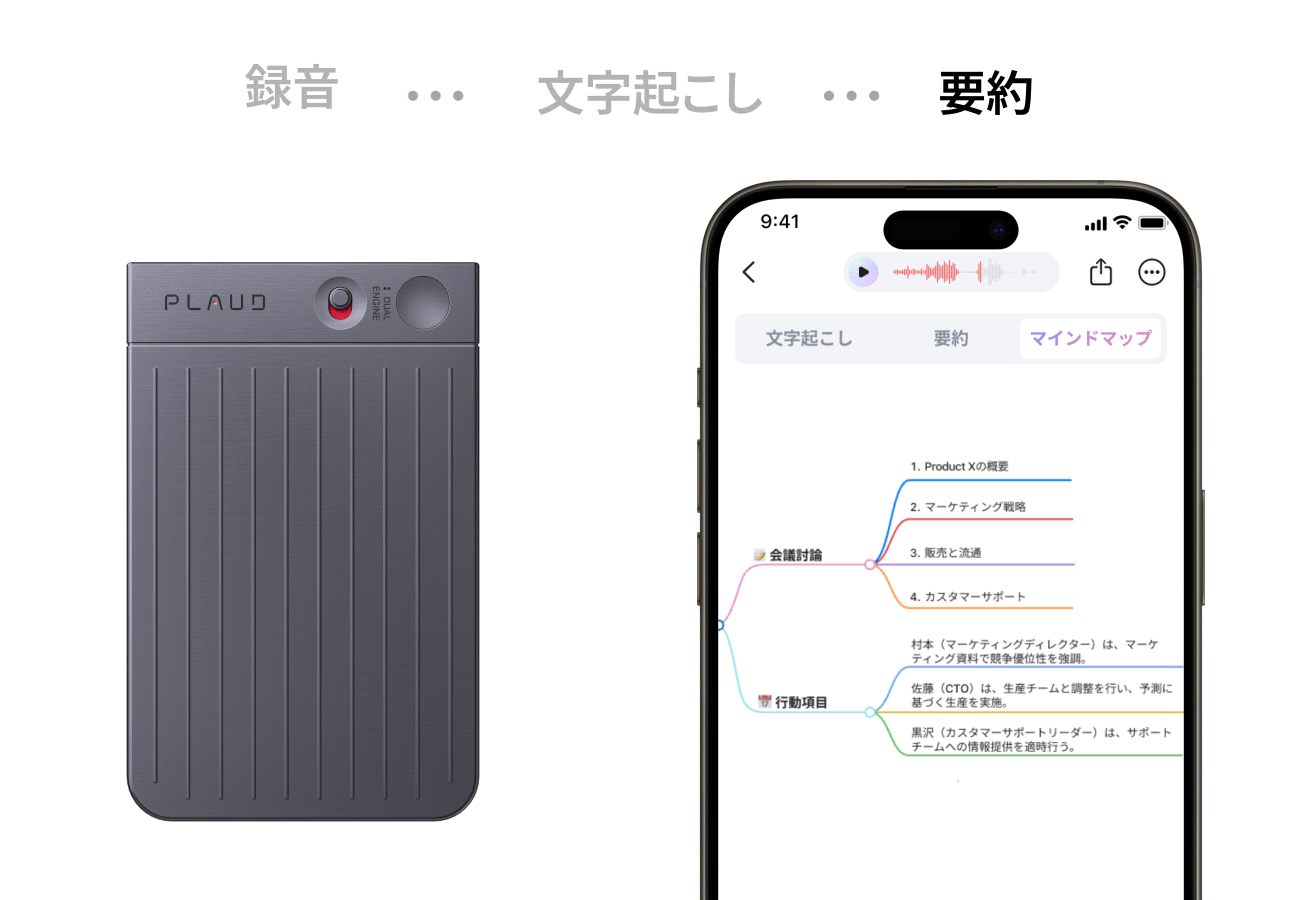
Plaud NotePin(プラウドノートピン)は、指でつまめる超小型・軽量(23g)のウェアラブルAIボイスレコーダーです。服にクリップやマグネットで装着し、日常会話、会議、取材などの音声を録音し、AIが自動で高精度な文字起こし、要約、マインドマップ化まで一貫して行います。







