AI音声ツールは、議事録作成や動画ナレーション、スマホの音声入力など、日常からビジネスまで幅広く使われています。
一方で「思ったより誤認識が多い」「読み上げが機械的に聞こえる」「会議の文字起こしが崩れる」といった悩みも少なくありません。
AIの進化により体験は改善しつつありますが、現時点で人間の話し方や聞き取りを完全に再現するのは難しいと指摘されています。
この記事では、AI音声ツール(音声認識・音声合成・音声読み上げ)が完璧ではない理由を、リサーチ結果の引用を交えながら整理し、弱点を踏まえた現実的な使い方まで解説します。


AI音声ツールは「万能」ではなく、弱点を前提に選ぶのが現実的です

AI音声ツールは、TTS(Text-to-Speech)やASR(Automatic Speech Recognition)を基盤に、テキストと音声を相互変換する技術です。
ただし現時点では、人間の自然な話し方を完璧に再現できないこと、そして誤認識やノイズの影響などの弱点が残ることが複数の情報源で共通して指摘されています[1][5]。
2026年現在は「Aqua Voice」のような音声入力ツールの進化で従来の「使えない」印象が改善しつつある一方、短い語句の文脈認識やノイズ耐性には課題が残り、音声と手入力を組み合わせるハイブリッド運用がトレンドとされています[9]。
弱点が生まれる背景は「音声の曖昧さ」と「環境依存」にあります

イントネーションや発音が不自然になりやすいです
音声合成(TTS)は進歩しているものの、抑揚・間・感情表現などは人間の話し方と比べて機械的になりやすいとされています。
リサーチ結果でも、イントネーションの不自然さは現時点の限界として挙げられており[1][5]、とくに固有名詞、専門用語、文の切れ目(句読点相当)の表現で違和感が出る可能性があります。
また、高品質な音声合成ほど設計・調整・運用のコストがかかる傾向がある点も指摘されています[4][5]。
誤認識・誤読は「話し方の揺れ」で起きやすいです
音声認識(ASR)は、発話が明瞭であるほど精度が上がりやすい一方、言い間違い、滑舌、口癖の影響を受けます。
リサーチ結果では「『あー』『えー』などが混ざると誤字脱字が発生し、後編集が必要」といった弱点が挙げられています[1][2][7]。
このため、AI音声ツールを導入しても「編集工数がゼロになる」とは限らず、業務設計の段階で見込みを立てておく必要があります。
ノイズや複数人発話で精度が落ちやすいです
ASRは周囲環境の影響を強く受けます。
周囲の騒音、反響、マイク品質、距離、同時発話などが重なると文字起こしが崩れやすく、リサーチ結果では騒音や複数人同時発話で精度が30%低下するという指摘もあります[3][6][8]。
静かな環境が推奨される理由はここにあり、会議室・オンライン会議・現場作業など、利用シーンによっては追加対策が必要になります。
方言・訛りは標準語より難易度が上がります
方言や訛りは、発音やアクセント体系が標準語と異なるため、認識精度が落ちやすいとされています。
リサーチ結果でも、標準語以外は精度が低く、カスタム学習が必要と指摘されています[3][8]。
多拠点のコールセンターや地方の現場ヒアリングなどでは、導入前の検証(PoC)で精度差を確認することが重要です。
発話者識別や文脈理解が不十分な場面があります
複数人の会話では「誰が話したか(話者分離)」が重要になります。
しかしリサーチ結果では、複数人会話で誰の発言か分からず支離滅裂なテキスト化が起きる可能性があるとされています[3][9]。
また、短い相づちや断片的な発話は文脈が不足し、意味が取りにくい形で出力されることがあります。
高品質を求めるほどコストが増えやすいです
音声合成・音声認識の品質向上には、モデルの利用料、学習データ、運用体制、編集工程などが関係します。
リサーチ結果でも、高品質音声生成は導入・運用費用がかかる点が弱点として挙げられています[1][4]。
そのため、全業務を一気に置き換えるより、費用対効果が出やすい範囲から段階導入する考え方が現実的です。
倫理・著作権(声の権利)に注意が必要です
AI音声ツールは便利な一方、声の利用がブランド不一致を起こしたり、権利侵害につながったりする可能性があると指摘されています[1]。
とくに「本人の許諾があるか」「利用範囲が契約上許されるか」「第三者の声に似せていないか」など、運用ルールの整備が欠かせません。
技術面だけでなく、法務・広報・人事の観点も含めて判断することが望ましいです。
弱点が出やすい場面と、現場で起きることの例
例1:会議の文字起こしで、話者が混ざって読みにくくなります
複数人が発言する会議では、同時発話や相づちが頻発します。
このとき話者識別が不十分だと、発言者ラベルが崩れたり、文章がつながって見えたりして、議事録として使いにくい結果になる可能性があります[3][9]。
対策としては、指向性マイクの利用、発言時のルール(かぶせない)、重要箇所のみ人が要約するなどが考えられます。
例2:騒がしい場所での音声入力が、想定以上に誤認識します
カフェや移動中、現場作業の近くなどで音声入力を行うと、周囲音を拾って誤認識が増えることがあります。
リサーチ結果でも、ノイズや雑音が精度に大きく影響し、場合によっては30%低下するという指摘があります[3][6][8]。
この場合は、静かな場所に移動する、ノイズキャンセリングマイクを使う、短文ではなく文脈のある文章で話すなどが有効と考えられます。
例3:読み上げ音声が「機械的」に聞こえ、ブランドと合わない場合があります
商品紹介動画や社内研修のナレーションでTTSを使うと、イントネーションが不自然で「硬い印象」を与えることがあります。
リサーチ結果でも、人間の自然な話し方の再現には限界があるとされ[1][5]、品質改善にはコストがかかる傾向が示されています[4][5]。
対策としては、句読点・改行で間を設計する、固有名詞の読みを辞書登録する、重要コンテンツはプロ声優さんの収録と併用する、といった方法が現実的です。
例4:方言のヒアリングが多い業務で、標準語前提の設定が足かせになります
地方拠点の営業メモやインタビューの文字起こしでは、方言や訛りが頻出します。
リサーチ結果の通り、方言対応は難しくカスタム学習が必要になる場合があります[3][8]。
この場合は、まず標準語話者のデータで精度を確認し、その後に方言話者のデータを追加して評価するなど、段階的な検証が適しています。

\出荷台数100万台突破!今人気のAIボイスレコーダー/




AI音声ツールの弱点を踏まえた要点整理
AI音声ツールは、音声認識(ASR)と音声合成(TTS)を中心に実用が進んでいます。
しかしリサーチ結果では、次の弱点が繰り返し指摘されています。
- イントネーション・発音の不自然さが残りやすいです[1][5]。
- 誤認識・誤読が起き、後編集が必要になりやすいです[1][2][7]。
- ノイズや複数人発話で精度が下がりやすいです[3][6][8]。
- 方言・訛りは精度が落ちやすく、カスタム学習が必要な場合があります[3][8]。
- 話者識別・文脈理解が不十分な場面があります[3][9]。
- 高品質化にはコストがかかりやすいです[1][4][5]。
- 倫理・著作権の観点で運用ルールが必要です[1]。
2026年現在は「Aqua Voice」などの進化で体験が改善しつつある一方、弱点がゼロになったわけではなく、ハイブリッド(音声+手入力)活用が現実的なトレンドとされています[9]。
失敗しにくい始め方は「用途を絞って、編集前提で設計する」ことです
AI音声ツールは、弱点を理解したうえで使うほど成果が出やすいと考えられます。
まずは次のように、目的と条件を絞るのが有効です。
- 静かな環境で、1人話者のメモ作成から始めます。
- 固有名詞・専門用語は辞書登録や読みの指定を行います。
- 「100%自動化」ではなく、後編集を前提に工数設計します。
- 会議用途はマイク環境と発話ルールを整備し、要約は人が担う運用も検討します。
- 音声合成はブランド要件を確認し、必要に応じて人の収録と併用します。
音声入力ツールの進化で選択肢は増えています。
一方で、短い語句の文脈認識やノイズ耐性などの課題は残るとされるため[9]、小さく試して、自社の環境での精度と運用負荷を確認しながら拡張する姿勢が適切です。
【PLAUD Noto Pin】”あなたの第二の脳になる”
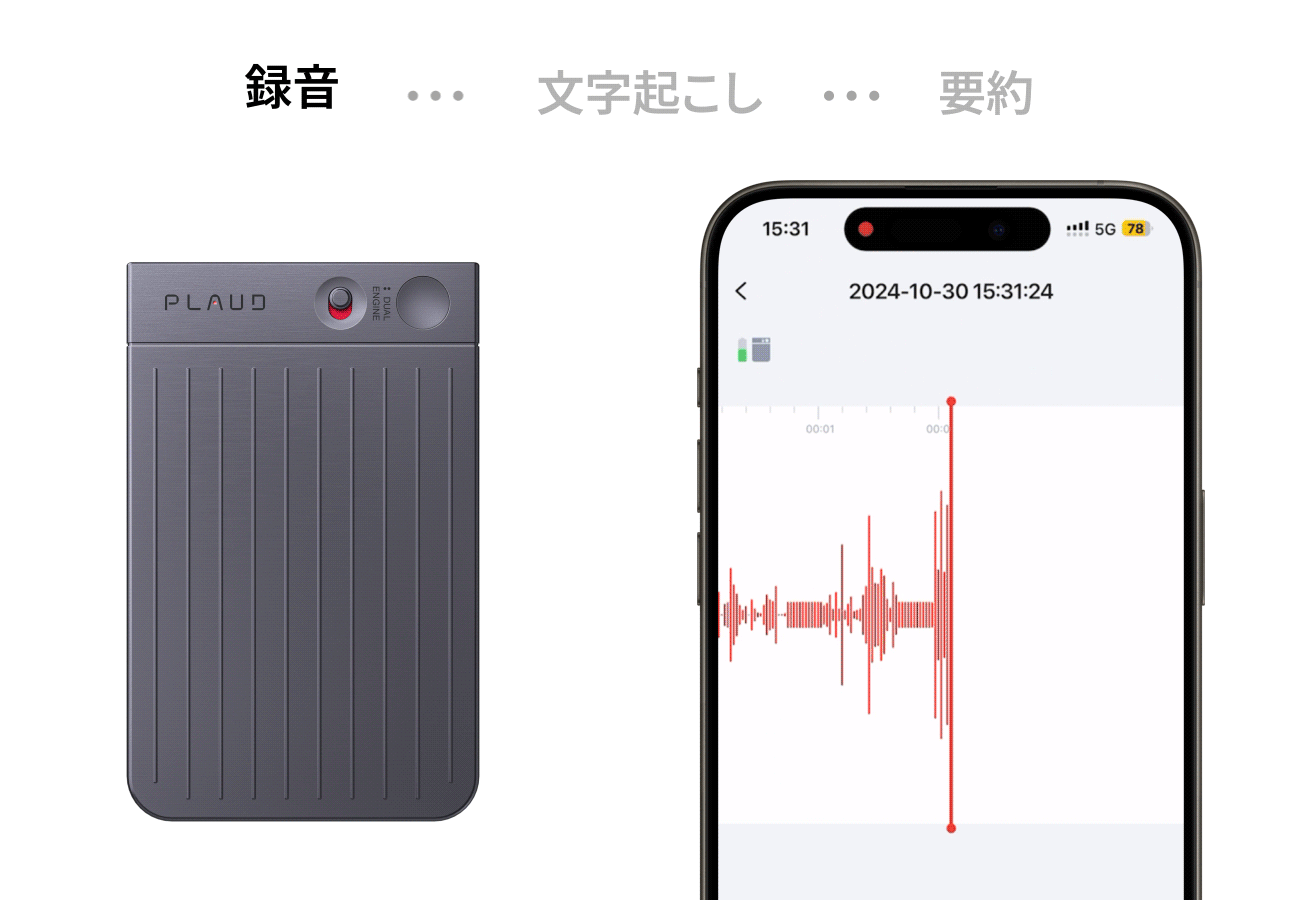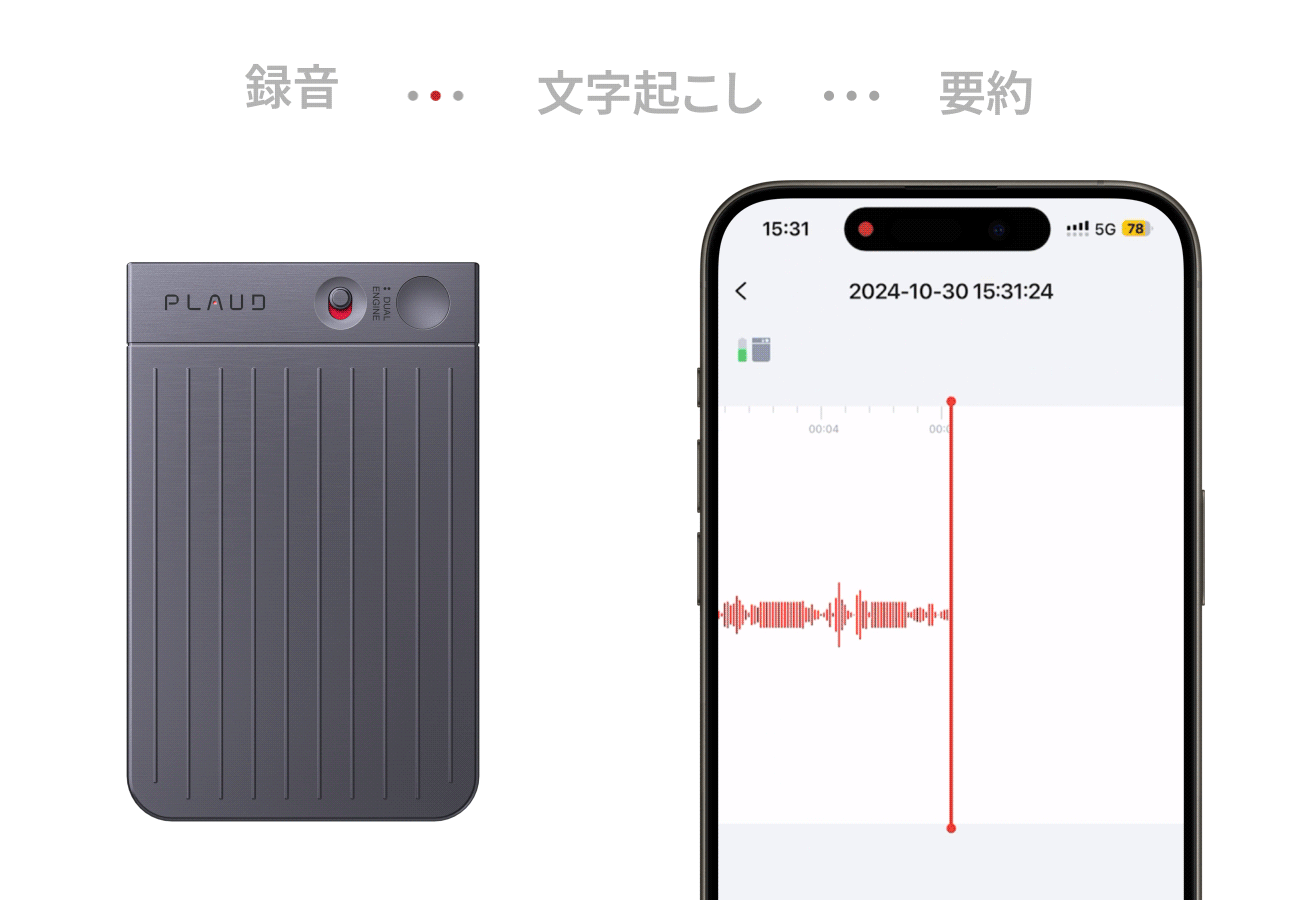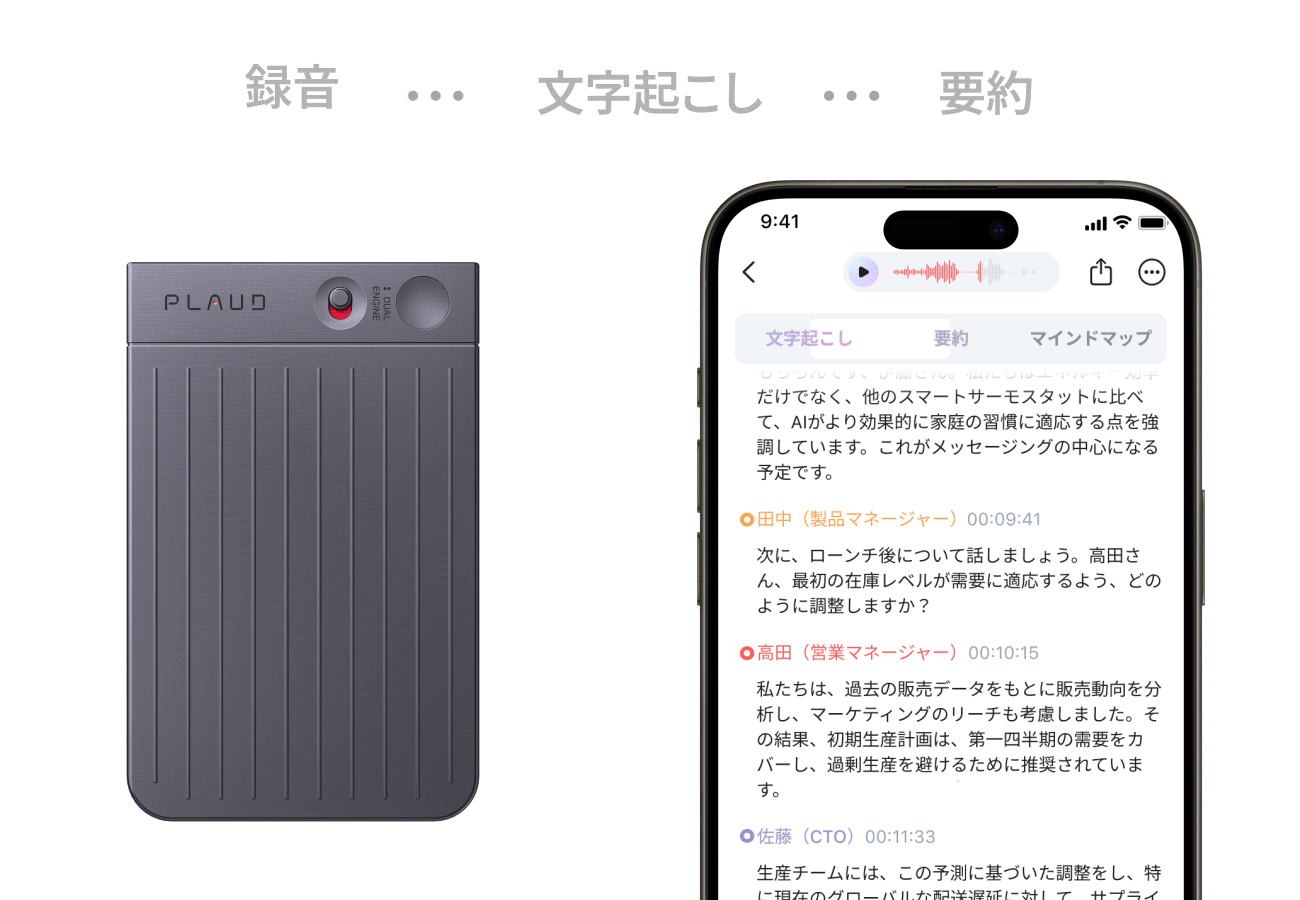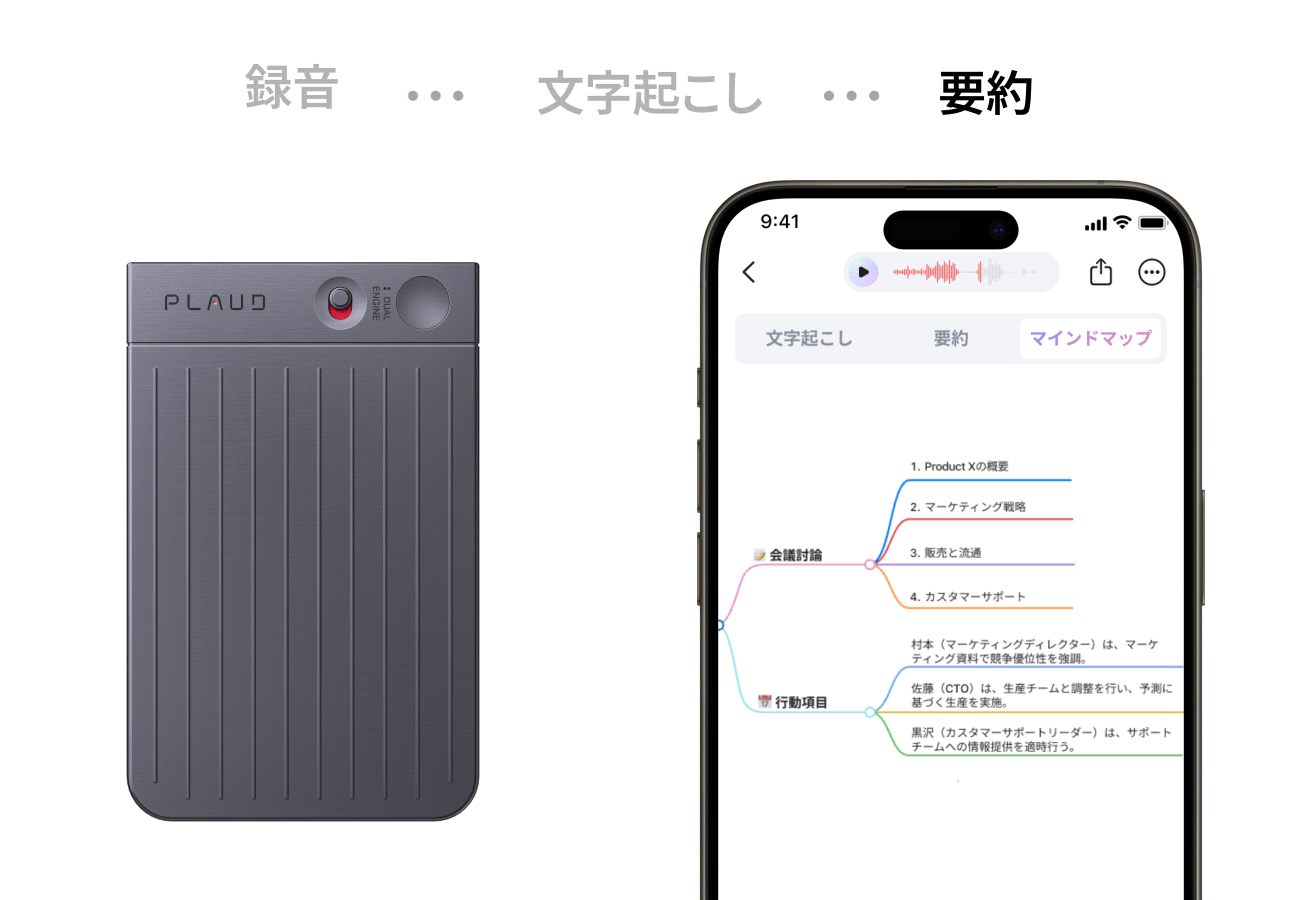
Plaud NotePin(プラウドノートピン)は、指でつまめる超小型・軽量(23g)のウェアラブルAIボイスレコーダーです。服にクリップやマグネットで装着し、日常会話、会議、取材などの音声を録音し、AIが自動で高精度な文字起こし、要約、マインドマップ化まで一貫して行います。







