AIレコーダーで文字起こしをしたとき、「同じ日本語の会議なのに、ある日はほぼ完璧で、別の日は誤変換だらけになる」と感じたことがある方も多いと思われます。
その差は、ツールの性能差だけで説明できないケースが少なくありません。
専門サイトの比較・実証では、AI議事録ツールの精度は主に「音の質×発話の仕方×ツール特性」で決まり、とりわけ録音環境や音質といった「現場差」が大きいと指摘されています。[1][2][4][7]
本記事では、AIレコーダーの精度に差が出る理由を、録音・話者・ツールの3視点で整理し、現場で再現しやすい改善の考え方まで解説します。


精度差の中心は「現場の音」と「運用条件」です

AIレコーダーの精度に差が出る最大の理由は、音声認識(ASR)が「クリアな音声入力」を前提に性能を発揮する仕組みであるためです。
そのため、背景ノイズ、反響、マイク距離、同時発話、話し方の癖などが少し変わるだけで、認識結果が大きく変動する可能性があります。[1][2][3]
もちろんツール間の差もありますが、2026年時点の分析でも、WhisperやConformer系などの先進モデルによりノイズ耐性は向上している一方、最終的な精度は「現場条件」に強く左右されるとされています。[1][4][7]
精度に差が出る主な要因は6つです
録音環境(ノイズ・反響)が最も影響します
比較検証では、AIレコーダーは静かな会議室などでは高精度になりやすい一方、カフェやオープンスペースのように雑音が多い環境では精度が急落しやすいと報告されています。[1][2][3]
特に影響が大きいのは次の要素です。
- 空調音、キーボード音、紙の擦れなどの定常・突発ノイズ
- 壁や天井の反射による反響(残響)
- 周囲の第三者の会話(同じ帯域の音が混ざる)
ASRは「声」と「声以外」を分離して推定しますが、ノイズが増えるほど推定が難しくなり、誤変換が増える可能性があります。[1][2]
マイク距離と音質が「推測の量」を増やします
マイクから話者までの距離が遠いほど、声の成分が弱まり、周囲音の比率が高くなります。
その結果、AIは欠けた音を言語モデルで補完しようとするため、「それっぽい別の単語」へ置き換わる誤変換が増えると考えられます。[1][7][8]
また、専用デバイスとスマホアプリの比較では、マイクアレイなど物理マイク性能の差が精度格差を生むと指摘されています。[1][4][7]
同時発話・複数人会話は構造的に難易度が上がります
2人以上が同時に話すと、音声が重なり、単語の境界や話者の切り替わりが曖昧になります。
この状態では、認識そのものだけでなく、誰が話したかを分ける話者分離(ダイアライゼーション)も難しくなり、結果として誤変換や話者の取り違えが増える可能性があります。[3][4][5]
一方で、静かな環境の1対1インタビューなどは、相対的に高精度になりやすいとされています。[3][4]
話者の特性(方言・なまり・話速)が誤りを生みます
方言、なまり、滑舌、話す速さ、語尾の伸ばし方などは、音響的なばらつきを増やします。
リサーチ結果でも、話者要因は認識エラーの原因になり得て、聞き取りやすい話し方にするほど精度が上がる傾向が示されています。[1][2][8]
専門用語・固有名詞は「学習不足」で落ちやすい領域です
ASRは一般的な語彙には強い一方、社内用語、製品名、人名、略語などは誤りが増えやすいとされています。[2][7]
言語モデルの進化で改善は進んでいますが、現場では依然として固有名詞の修正コストが大きい場面があります。
ツール特性(モデル・デバイス・話者識別)が結果を左右します
同じ音源でも、ツールによって認識結果が変わることがあります。
2026年時点の比較では、WhisperやConformerなどの先進モデルの進化でノイズ耐性は向上しつつ、専用デバイス(例:PLAUD NotePin)とスマホアプリでは、マイクアレイなどの物理性能差が出やすいとされています。[1][4][7]
また、PLAUD NotePinやAutoMemo Rは話者識別が可能で、Pixelのアプリより優位とされる比較もあります。[4]
ただし、ツールが高性能でも現場条件が悪いと精度は変動し、精度が90%未満だと修正負担が大きくなりやすい、という指摘もあります。[4][6][9]
現場で起きやすい「精度差」の具体例
例1:同じ会議室でも「空調」と「反響」で結果が変わります
参加者や議題が同じでも、空調が強い日や、扉の開閉で反響条件が変わる日があります。
このとき、低周波の定常ノイズや残響が増えると、子音が埋もれやすくなり、誤変換が増える可能性があります。[1][2][3]
対策としては、録音位置を壁から離す、机上の中心に置く、可能なら空調の風が当たる位置を避けるなど、音の条件を一定にする運用が有効と考えられます。
例2:スマホを机の端に置くと、遠い人の発話が崩れます
スマホを机の端に置くと、近い人は明瞭でも、遠い人は声が小さくなり、周囲音が相対的に大きく入ります。
この状態ではAIが推測に頼る割合が増え、文脈に引っ張られた誤変換が起きやすいと考えられます。[1][7][8]
専用デバイスが有利になりやすい背景として、マイクアレイの物理性能差が挙げられています。[1][4][7]
例3:複数人が被せて話すと、話者識別も文字起こしも乱れます
議論が白熱して発話が重なると、単語の切れ目や話者の境界が曖昧になります。
結果として、文章が混ざる、話者ラベルがずれる、重要な数字が欠落するなどが起きやすくなります。[3][4][5]
運用面では、司会者さんが発言順を整理する、相づちを短くする、結論部分だけでも区切って話すなど、同時発話を減らす設計が精度の安定に寄与すると考えられます。
例4:固有名詞が多い会議は「人の手直し」が増えます
新製品名、取引先名、人名、略称が多い会議では、一般語彙より誤変換が増えやすいとされています。[2][7]
この場合、ツール変更だけで解決しないこともあり、事前に用語集を共有する、発話時に正式名称で言い直すなど、入力側の工夫が現実的な対策になり得ます。

\出荷台数100万台突破!今人気のAIボイスレコーダー/




まとめ:ツール選びより先に「音の条件」を整えるのが近道です
AIレコーダーの精度に差が出る理由は、ツール性能だけではなく、録音環境・マイク距離・同時発話・話者特性・専門用語・ツール特性が複合的に影響するためです。
リサーチ結果でも、精度の差は「現場差」が主因になりやすく、まずは音質優先(近距離・ノイズ低減)の改善が効果的とされています。[1][2]
そのうえで、話者識別の必要性や利用シーンに応じて、専用デバイスやアプリを比較検討する流れが合理的と考えられます。[4][7]
次に取りやすい一手は「録音の標準化」です
精度を安定させたい場合、最初に取り組みやすいのは、録音のやり方をチームで揃えることです。
例えば、レコーダーの置き場所を固定する、発言は被せない、固有名詞はゆっくり言い直すなど、運用で吸収できる部分が少なくありません。
もし現在の修正負担が大きい場合は、まず「静かな場所で近距離録音」を試し、改善幅を確認したうえで、マイクアレイ搭載の専用デバイスや話者識別対応ツール(PLAUD NotePin、AutoMemo Rなど)の導入を検討すると、判断がしやすくなると思われます。[1][4][7]
【PLAUD Noto Pin】”あなたの第二の脳になる”
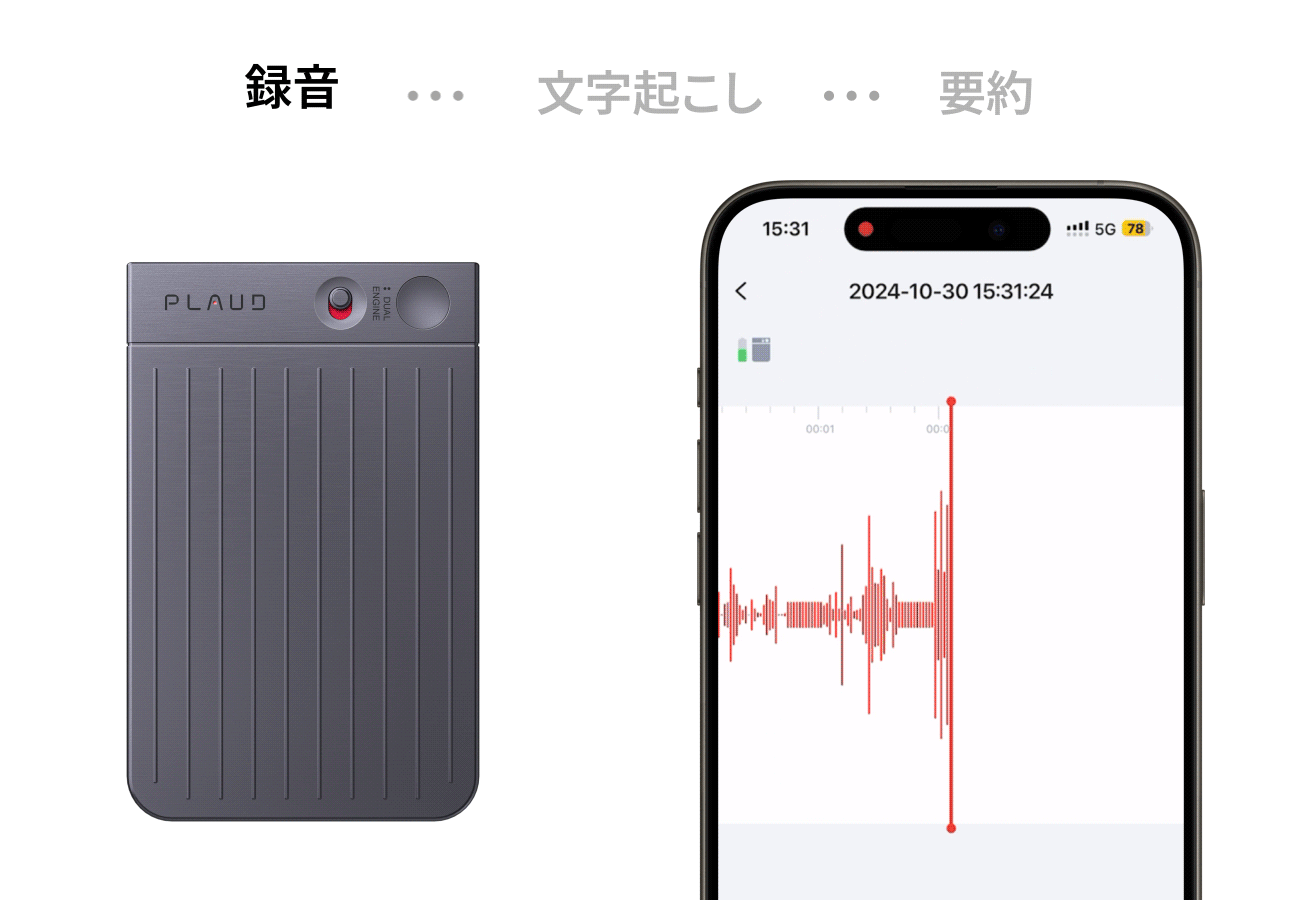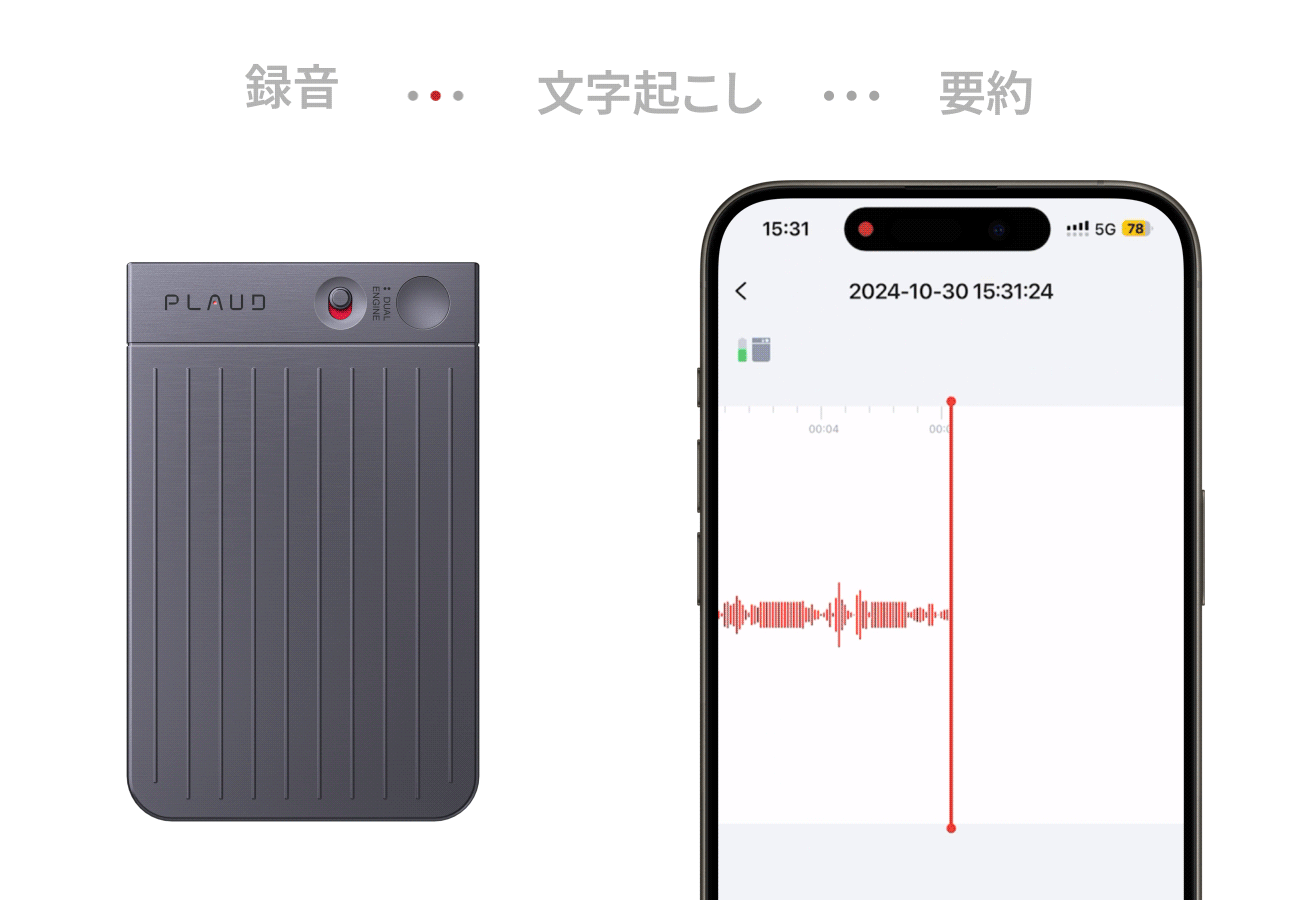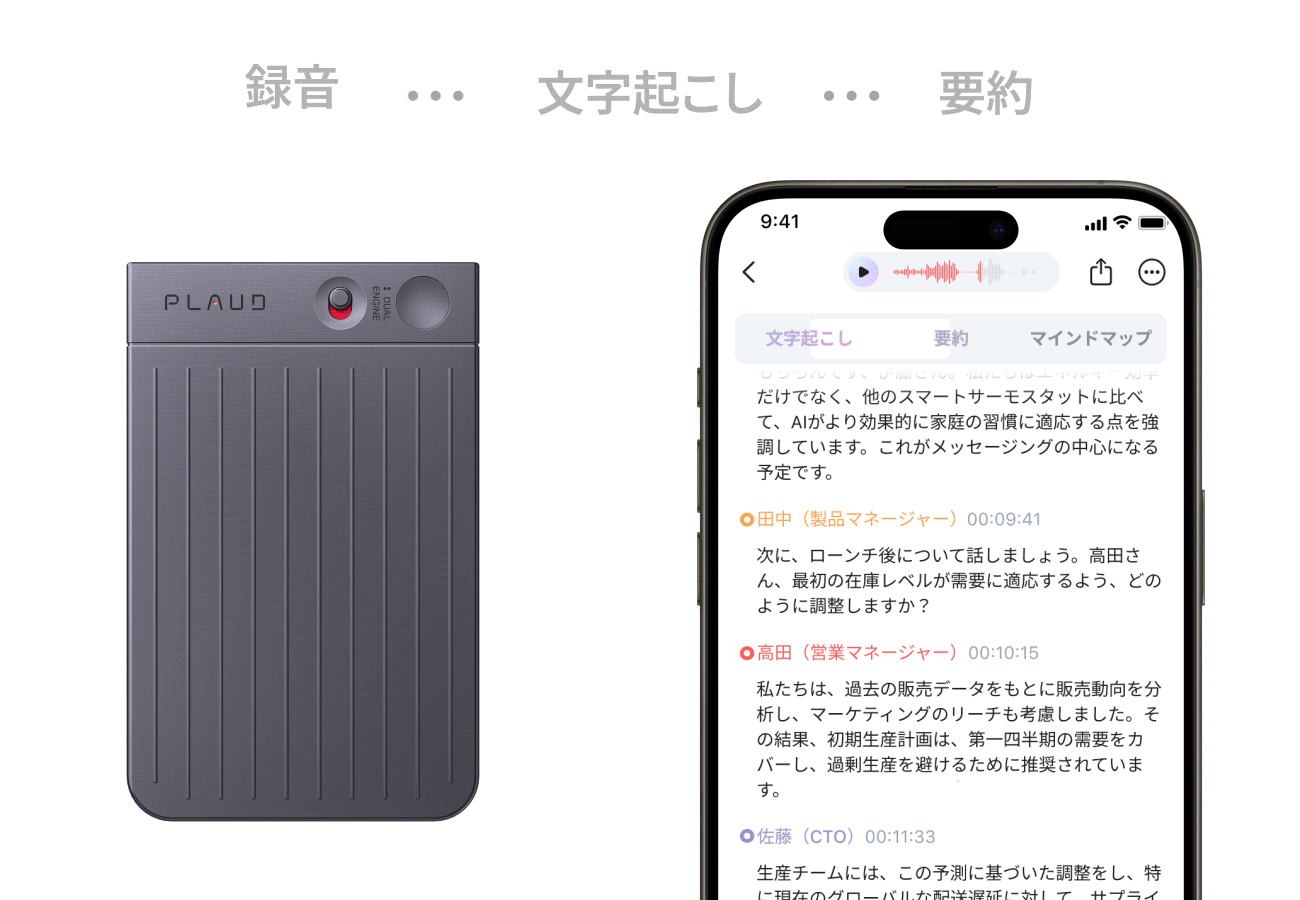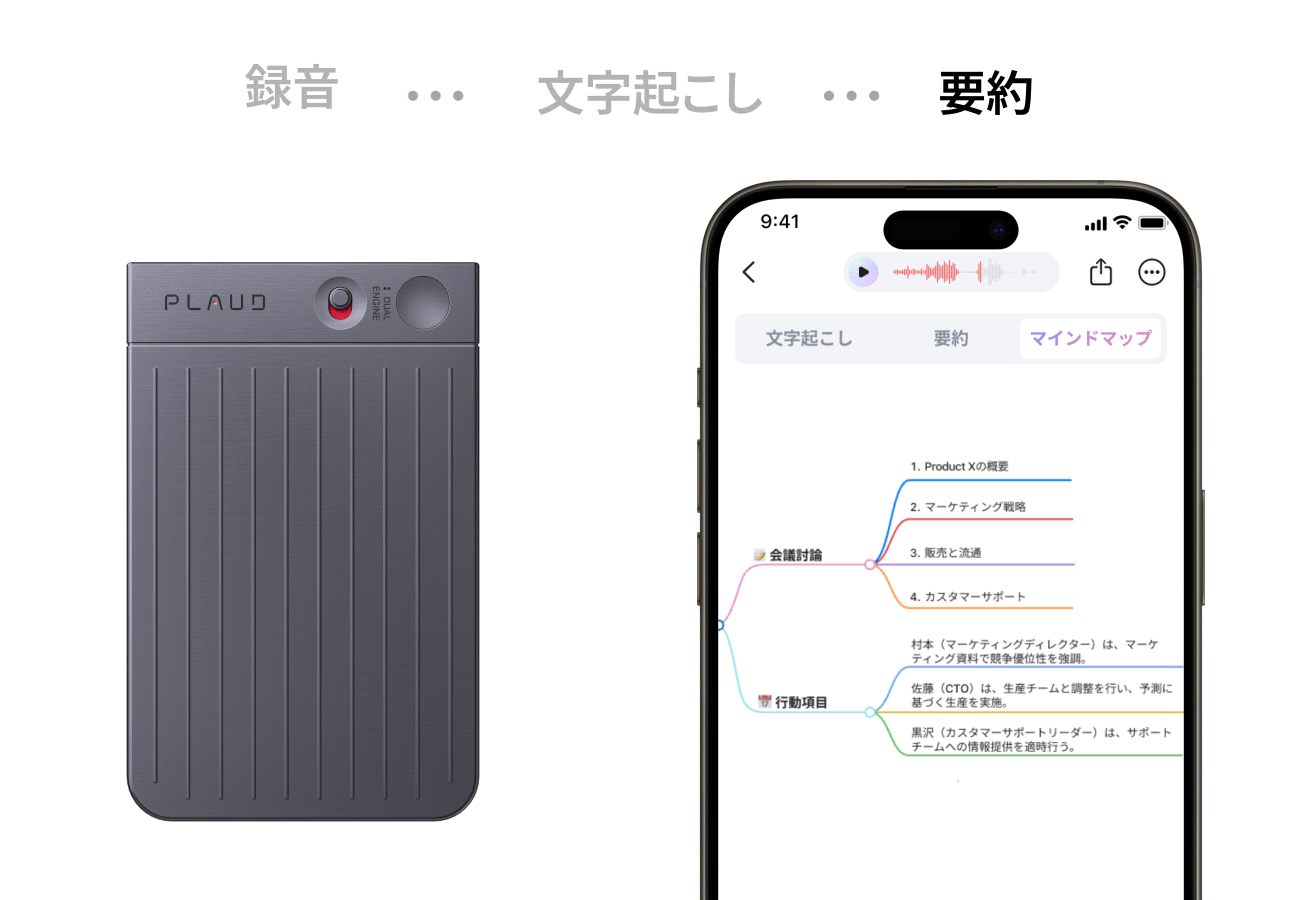
Plaud NotePin(プラウドノートピン)は、指でつまめる超小型・軽量(23g)のウェアラブルAIボイスレコーダーです。服にクリップやマグネットで装着し、日常会話、会議、取材などの音声を録音し、AIが自動で高精度な文字起こし、要約、マインドマップ化まで一貫して行います。







