
※当ページのリンクには広告が含まれています。
AIレコーダーで会議を録音し、文字起こしまで自動化したいと考える方は増えています。
一方で、実際に使ってみると「固有名詞が別の単語になる」「誰が話したのかが入れ替わる」「文章が意味不明になる」といった誤認識に悩むケースも少なくありません。
2025年4月時点でも、オフィスノイズや発音癖に起因する音声認識ミスを減らすためのガイドが公開されるなど、誤認識は“使い方で差が出る課題”として注目されています。
この記事では、AIレコーダー(例:PLAUD NOTEなど)の誤認識が起きる理由を整理し、現場で再現性の高い対策を具体的に解説します。




誤認識は「録音・話し方・用語・話者」の4点を押さえると減らせます

AIレコーダーの誤認識は、主に背景ノイズと音質、方言・訛りや早口、専門用語・固有名詞、話者識別(話者分離)の失敗で発生しやすいとされています。
そのため対策も、録音環境の改善、運用ルールの整備、後処理(校正)の3層で設計すると効果が出やすいです。
とくにカフェなど雑音が多い環境では、文字起こし結果が意味不明な文章になる「ポエム化」の失敗報告もあり、AIの出力を過信しない運用が重要だと考えられます。
AIレコーダーが誤認識する主な原因

背景ノイズ・反響・マイク距離で精度が急落しやすいです
誤認識の最大要因として挙げられやすいのが、背景ノイズや反響などによる音声品質の低下です。
カフェ、オープンスペースのオフィス、反響の強い会議室では、空調音や食器音、周囲会話が混ざりやすく、AIが話者の声を正しく抽出できない可能性があります。
また、マイクが話者から遠い場合、声が小さくなり、ノイズ比率が上がるため誤変換が増えるとされています。
「録れている」ことと「認識できる」ことは別という点が重要です。
方言・訛り・早口は学習データとの差で誤変換が起きやすいです
音声認識は標準語ベースの学習データに依存しやすいため、方言や訛り、独特のイントネーションがあると誤認識が増えると言われています。
東北・関西などのなまりで単語が別語に置き換わる例も報告されています。
早口や語尾が消える話し方も、単語境界が曖昧になり、誤変換や脱落が起きる可能性があります。
専門用語・固有名詞が崩れると、文脈エラーが連鎖しやすいです
議事録で致命的になりやすいのが、社名、人名、製品名、略語、業界用語の誤認識です。
固有名詞が誤変換されると、その後の文章が文脈的に成立しなくなり、修正箇所が増える傾向があります。
専門用語の誤認識は、表記ゆれ(例:「見る」「観る」)のような軽微なものから、意味が変わるレベルまで幅があるとされています。
話者識別(話者分離)は3名以上・同時発話で崩れやすいです
複数人会議では「誰が話したか」を分ける話者識別が重要です。
しかし、声質が似ている、発話が重なる、3名以上で頻繁に会話が切り替わる状況では、ラベルずれや混同が起きやすいとされています。
結果として、発言者が入れ替わった議事録になり、確認コストが増える可能性があります。
現場で効く対策は「録音環境」「運用ルール」「校正」の組み合わせです
録音環境を整えると、誤認識の土台が改善されます
まず優先度が高いのは、入力音声の品質を上げることです。
2025年4月時点でも、専用デバイスの収音性能向上により誤変換を低減する事例が増えているとされ、PLAUD NOTEのようなAIレコーダーが選択肢として挙げられています。
実務上は、次のような対策が取りやすいです。
- 静かな場所を選ぶ(空調・雑談・食器音が少ない環境)
- 話者の近くに置く(距離が短いほど有利)
- 外付けマイクや専用レコーダーを使う(収音品質の底上げ)
- 反響が強い部屋では、壁から離す、テーブル中央に置くなど配置を工夫する
環境改善は地味ですが、後工程の校正時間を大きく減らす可能性があります。
運用ルールを決めると、話者分離と聞き取りが安定しやすいです
同じツールでも、会議の進め方で精度は変わります。
AIエージェントの音声認識ミス削減ガイドでも、オフィスノイズや発音癖への対策が注目されているように、人側の協力が品質に影響すると考えられます。
導入しやすい運用ルールは次の通りです。
- 発言前に名乗る(「営業の田中さんです」など)
- 同時発話を避け、司会者が交通整理する
- 要点は短く区切って話す(長文の一息話法を避ける)
- 方言が強い場合は、可能な範囲で標準語を意識する
- 方言対応が期待できるツール・デバイスを選ぶ(例としてPLAUD NOTEが推奨されるケースがあります)
全員が完璧に守る必要はありませんが、重要会議ほどルールの効果が出やすいです。
後処理(校正)を前提にすると「ポエム化」のリスクを抑えられます
雑音の多い場所で録音した場合、文字起こしが意味不明な文章になる「ポエム化」が起きるという報告があり、校正の必要性が強調されています。
このため、AI文字起こしは一次原稿(ドラフト)として扱い、人が最終確認する運用が現実的です。
具体的には次のような後処理が有効です。
- 固有名詞(人名・社名・製品名)を先に洗い出して一括置換する
- 重要箇所のみ音声を聞き直し、全文の聞き直しを避ける
- 議事録の目的に合わせて要約・整形する(逐語にこだわりすぎない)
- 精度要件が高い場合は専門業者の活用も検討する(90%以上の精度確保がうたわれるケースがあります)
「AIがあるから校正不要」ではなく、「AIで校正コストを下げる」という設計が安全だと思われます。

\出荷台数100万台突破!今人気のAIボイスレコーダー/


誤認識が起きやすい場面別の具体例
カフェ録音でノイズが勝ち、文章が成立しないケース
カフェではBGM、食器音、周囲会話が常時入りやすく、音声認識が破綻しやすいです。
結果として、発言がつながらず、意味不明な文章になる「ポエム化」が起きる可能性があります。
対策としては、静かな席を選ぶ、話者の近くに置く、可能なら専用レコーダーや外付けマイクを使うことが有効です。
3名以上の会議で話者ラベルが入れ替わるケース
複数人がテンポよく会話する場面では、話者識別が追従できず、Aさんの発言がBさんとして記録されるなどの混同が起きやすいとされています。
対策としては、発言前に名乗る、司会者が同時発話を止める、席順を固定しレコーダーを中央に置くなどが挙げられます。
専門用語が崩れて議論の趣旨まで変わってしまうケース
IT、医療、製造、法務などでは略語や専門用語が多く、誤認識が起きると文脈エラーが連鎖する可能性があります。
例えば固有名詞が一般名詞に置き換わると、議題そのものが別物に見えてしまいます。
対策としては、会議前に用語リストを用意する、会議後に固有名詞から優先的に校正するなどが現実的です。
方言や訛りで単語が別語になり、要点がずれるケース
方言や訛りが強い場合、標準語ベースの認識では単語が別の語に置換されることがあります。
対策としては、重要な場面だけ標準語を意識する、ゆっくり区切って話す、方言対応が期待できるツールを選ぶなどが挙げられます。
誤認識対策は「入力の改善」と「過信しない設計」が要点です
AIレコーダーの誤認識は、背景ノイズ、方言・訛り、専門用語、話者識別の失敗で起きやすいとされています。
対策は次の3点に整理できます。
- 録音環境を改善する(静かな場所、近距離、外付けマイクや専用レコーダー)
- 運用ルールを整える(名乗り、同時発話回避、話し方の工夫)
- 校正を前提にする(ポエム化や固有名詞崩れに備える)
この3層で設計すると、文字起こしの実用性が上がりやすいと考えられます。
まずは「1回の会議」で小さく試すと失敗しにくいです
誤認識対策は、いきなり完璧を目指すより、重要度が中程度の会議で試し、改善点を特定する進め方が適しています。
具体的には、次の順で取り組むと判断がしやすいです。
- 同じ会議で「置き場所」だけ変えて精度差を確認する
- 次に「名乗り」「同時発話回避」など運用ルールを1つだけ追加する
- 最後に、専用デバイスや外付けマイクの導入を検討する
AIレコーダーは、適切な環境と運用で価値が出やすいツールです。
ご自身の会議体に合わせて、再現性の高い対策から順に試すことが望ましいと思われます。
【PLAUD Noto Pin】”あなたの第二の脳になる”
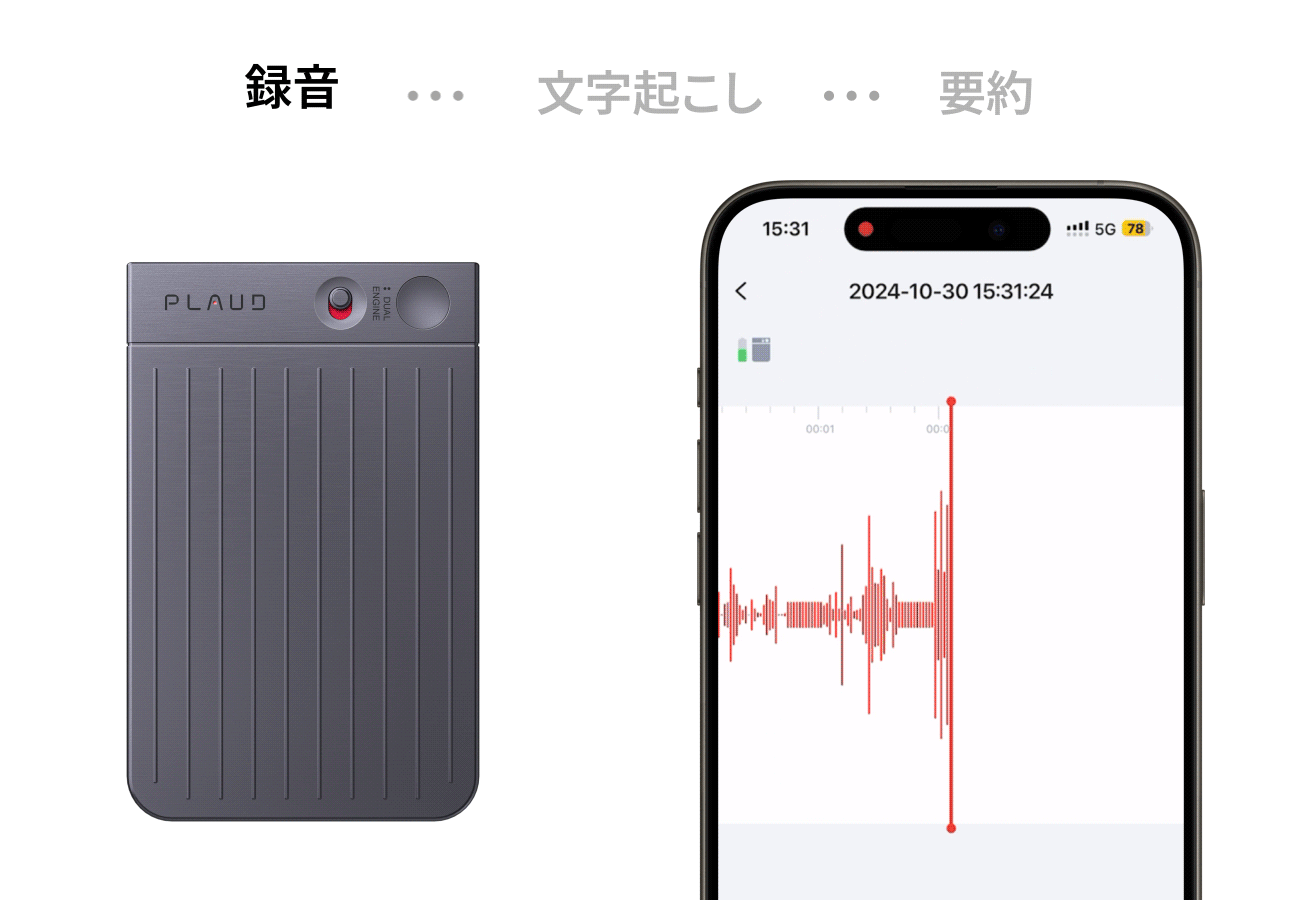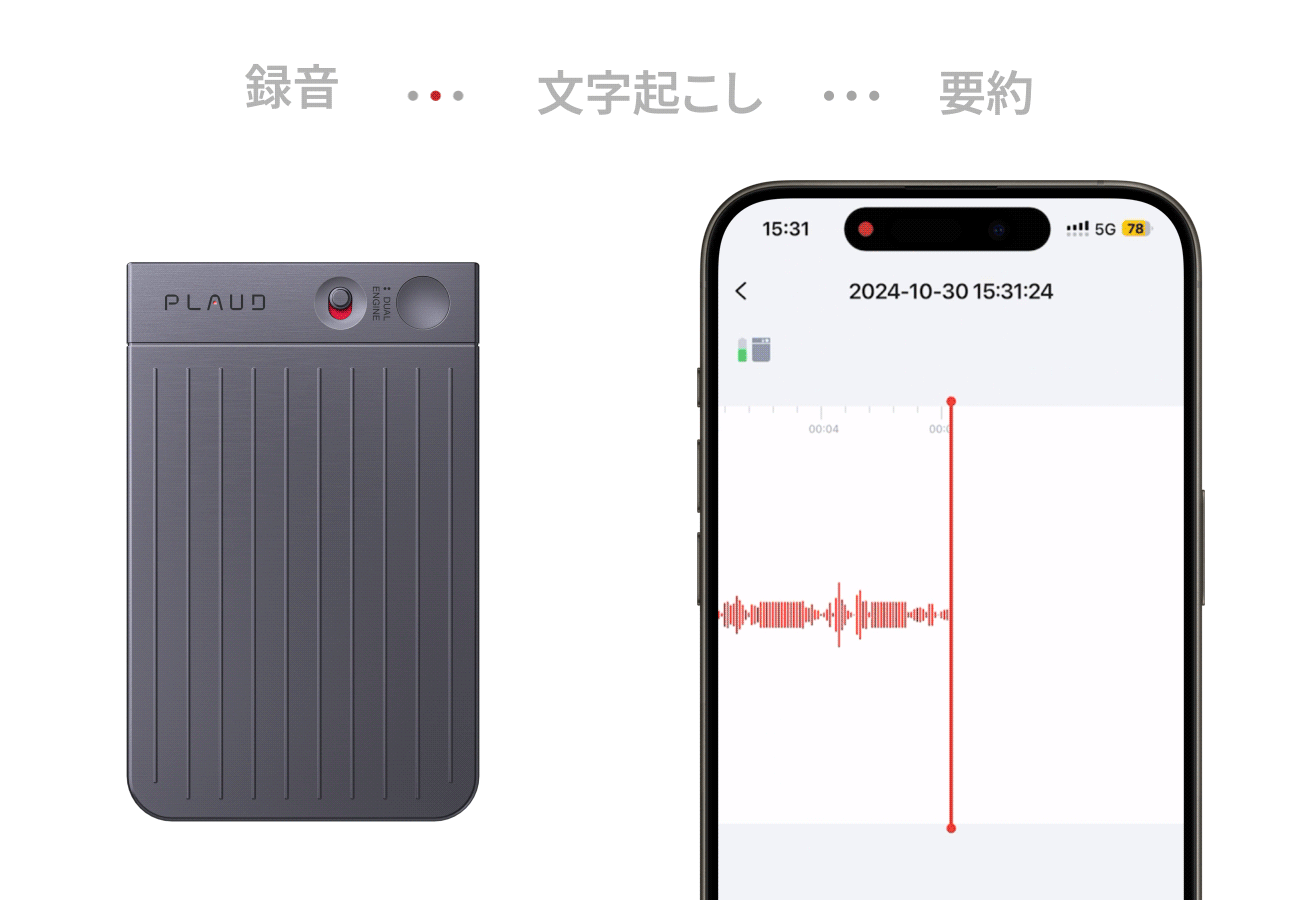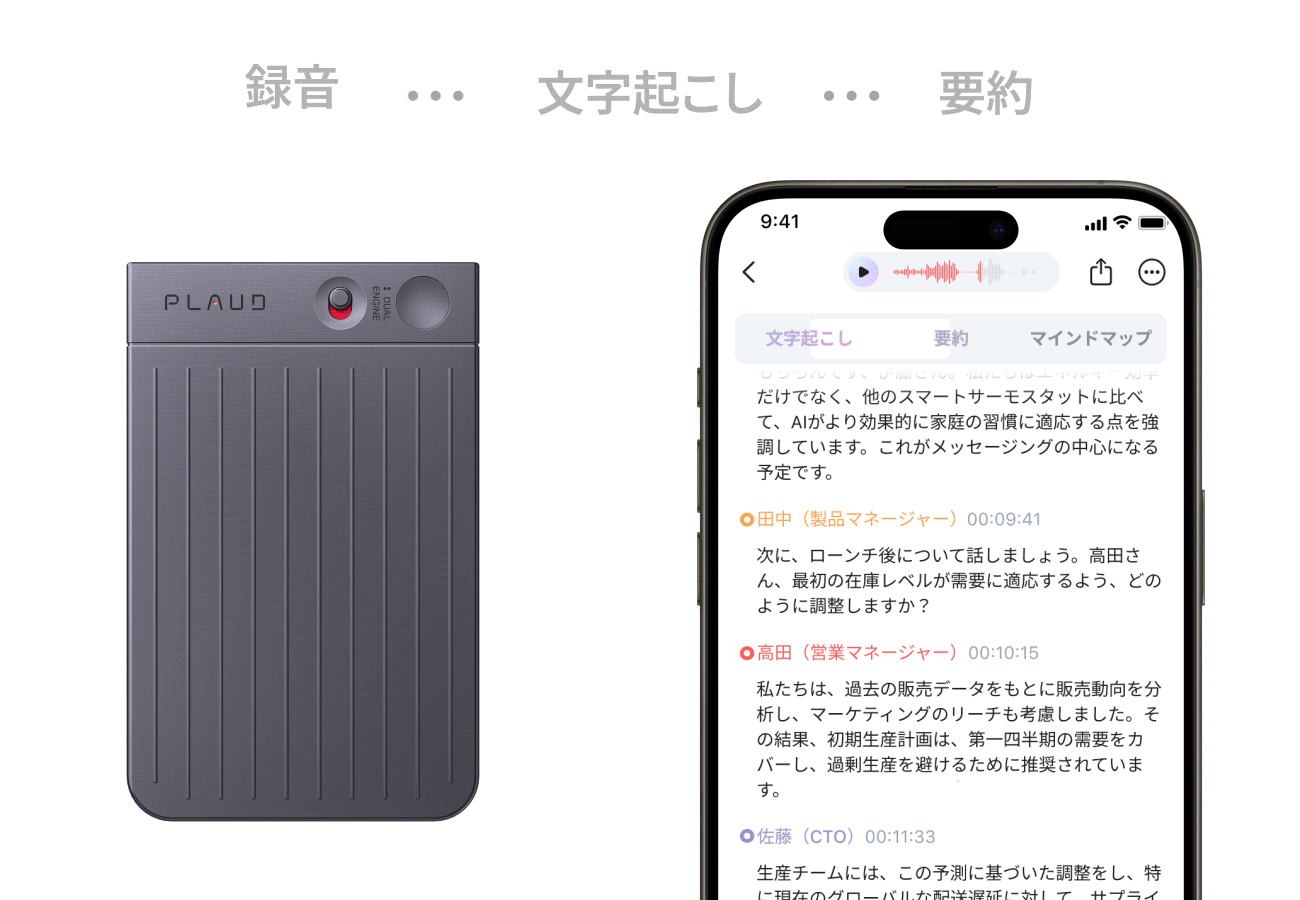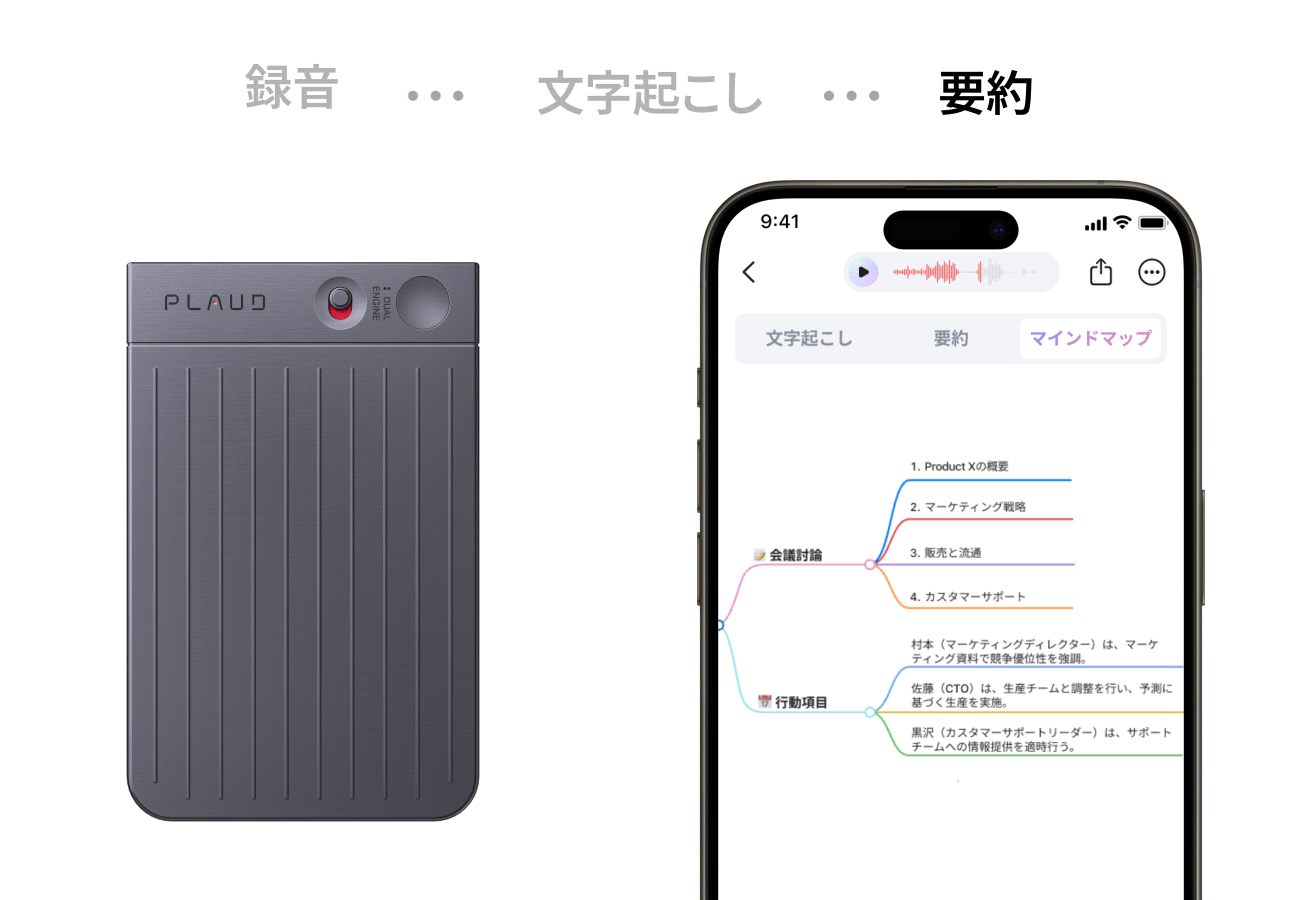
Plaud NotePin(プラウドノートピン)は、指でつまめる超小型・軽量(23g)のウェアラブルAIボイスレコーダーです。服にクリップやマグネットで装着し、日常会話、会議、取材などの音声を録音し、AIが自動で高精度な文字起こし、要約、マインドマップ化まで一貫して行います。







